Главный вопрос: одна таблица или много для разных инструментов?
При хранении OHLCV-данных для 30–50 фьючерсных тикеров возникает архитектурный выбор: создать одну общую таблицу или отдельную таблицу под каждый инструмент. Ответ однозначный — одна таблица.
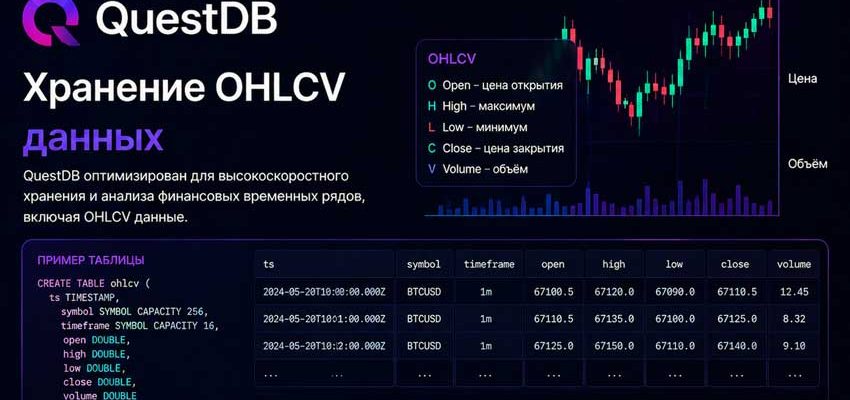
Правильная структура: одна таблица ohlcv
Все тикеры и все таймфреймы хранятся вместе, разделяются колонками symbol и timeframe
Почему НЕ отдельные таблицы на каждый тикер?
Минусы подхода «30 таблиц»:
- Кросс-тикерный анализ требует UNION ALL по всем таблицам — громоздко и неудобно
- Добавить новый инструмент = создать таблицу + обновить все запросы + обновить код робота
- ALTER TABLE при изменении схемы нужно выполнять 50 раз
- Сканирование рынка роботом — 50 отдельных запросов вместо одного
- Тип SYMBOL в QuestDB специально создан для повторяющихся строк — внутри хранит числа, фильтрация быстрая
Разные таймфреймы: как хранить?
Для разных таймфреймов есть два подхода в зависимости от объёма данных и сложности запросов.
Вариант А: всё в одной таблице (колонка timeframe)
Подходит для большинства задач. Запросы фильтруются по timeframe = ‘1h’. Схема — та же таблица ohlcv.
Вариант Б: отдельные таблицы по таймфрейму
Имеет смысл при очень большом объёме данных (миллиарды строк) или когда таймфреймы требуют принципиально разных настроек партиционирования:
ohlcv_1m — свечи 1 минута, все тикеры, PARTITION BY DAY
ohlcv_5m — свечи 5 минут, все тикеры, PARTITION BY WEEK
ohlcv_1h — свечи 1 час, все тикеры, PARTITION BY MONTH
ohlcv_1d — свечи 1 день, все тикеры, PARTITION BY YEAR
Внутри каждой таблицы по-прежнему все тикеры вместе — разделения по инструментам нет.
Партиционирование
Представь что у тебя есть 10 лет банковских выписок — тысячи листов бумаги. Ты хочешь найти все транзакции за июнь 2023 года.Без партиционирования — всё в одной огромной стопке и чтобы найти июнь 2023 — листаешь всё с самого начала, это медленно!
С партиционированием — документы разложены по папкам:
? 2021/
? 2022/
? 2023/
? январь/
? февраль/
? март/
? апрель/
? май/
? июнь/ ← открыл только эту папку
? июль/
...
? 2024/Нужен июнь 2023 — идёшь сразу в нужную папку. Остальное даже не трогаешь.
Партиционирование — это разделение одной большой таблицы на физически отдельные части (партиции) по какому-либо критерию, при этом для пользователя таблица остаётся единой. Запрашиваешь данные как обычно, а база сама решает в какие партиции заглянуть, а какие пропустить.
Ключевое слово — физически. Это не просто логическая группировка, данные реально лежат в разных папках на диске.
Когда партиционирование целесообразно
- Данные имеют естественное измерение для разделения, у нас это время.
- Таблица большая. Условная граница — от нескольких десятков миллионов строк. На маленьких таблицах накладные расходы на управление партициями съедят весь выигрыш в скорости.
- Запросы почти всегда затрагивают только часть данных. Если твои запросы всегда смотрят на последние 7 дней — незачем сканировать 3 года истории. Партиции по дням позволяют базе просто не открывать старые папки.
- Нужно удалять старые данные. Без партиций удаление миллионов старых строк — дорогая операция, база перестраивает индексы. С партициями — просто удаляешь папку целиком. Мгновенно.
Когда партиционирование НЕ нужно
Когда таблица маленькая и вырастет максимум до нескольких миллионов строк. Запросы всегда сканируют всю таблицу целиком — например справочники, конфиги, таблица тикеров с их метаданными. Данные не имеют временного или категориального измерения.
Классические базы данных — PostgreSQL, MySQL — позволяют партиционировать по любой колонке или по нескольким сразу. Но они и стоят других компромиссов: медленнее на временных рядах, сложнее в настройке.
Как тогда быстро искать по тикеру?
Для этого в QuestDB есть тип SYMBOL — он решает ту же задачу но другим способом. Внутри база строит словарь и индекс:
'BTC_USDT' → 1
'ETH_USDT' → 2
'SOL_USDT' → 3Фильтр WHERE symbol = 'BTC_USDT' работает не как поиск по тексту, а как поиск числа 1 — очень быстро. Если добавить явный индекс на колонку symbol — поиск становится ещё быстрее.
| Задача | Инструмент |
|---|---|
| Быстро читать диапазон дат | PARTITION BY DAY |
| Быстро фильтровать по тикеру | SYMBOL INDEX |
Партиционирование целесообразно когда данных много, они растут со временем, и запросы обращаются к ограниченному диапазону — тогда база работает только с нужным куском и не трогает остальное.
Тиковые данные — отдельный разговор
Тиковые данные (каждая сделка на бирже) принципиально отличаются от OHLCV и требуют отдельной таблицы всегда.
Почему тики хранятся отдельно
- Объём: OHLCV 1m за год — ~500 тыс. строк на тикер. Тики за год — сотни миллионов строк
- Структура данных другая: нет OHLCV, есть price, size, side (buy/sell), trade_id
- Партиционирование должно быть агрессивнее: PARTITION BY HOUR или даже BY MINUTE
- Запросы разные: тики нужны для построения стакана, VWAP, анализа потока ордеров
- Retention-политика разная: тики хранят 30–90 дней, OHLCV — годами
Итоговая архитектура
Финальная схема для торгового робота с историческими данными, индикаторами и сигналами:
| Таблица | Содержимое | Партиция | Примечание |
| ohlcv | OHLCV все тикеры + все ТФ | BY DAY | Основной источник данных |
| ticks | Каждая сделка на бирже | BY HOUR | Опционально, большой объём |
| indicators | MACD, Аллигатор и др. | BY DAY | Считаются из ohlcv |
| signals | Сигналы робота | BY DAY | BUY / SELL / HOLD + score(сила сигнала) |
Выводы
- Одна таблица ohlcv с колонками symbol и timeframe — оптимальная архитектура для 30–50 тикеров
- Тип SYMBOL в QuestDB специально оптимизирован для фильтрации по повторяющимся значениям
- PARTITION BY DAY — правильный выбор для OHLCV, позволяет быстро удалять старые данные
- Тиковые данные всегда в отдельной таблице: другой объём, структура, retention и паттерны запросов
- Индикаторы и сигналы робота — отдельные таблицы, считаются из ohlcv, не смешиваются с сырыми данными