

Ранее я публиковал свою первую программу «Тахометр трейдера» для получения исторических данных по всем акциям с Мосбиржи. Листинг программы есть в посте моего блога, а исполняемый exe файл для windows можно скачать с сайта tahometr.ru. Все исторические данные сохраняются в csv файлах. Это хороший вариант, но есть желание просто попробовать поместить все данные в базу данных, возможно при этом будет более комфортно работать с большими объемами информации, делать различные выборки, реализовать формирование тех же csv файлов в произвольном виде по запросам самого пользователя. Плюс в базе данных можно сохранять какие-либо данные между запусками программы или данные по работе того же торгового робота.
Возможно работа с БД ускорит работу с историческими данными, а возможно и нет, тут надо просто пробовать и тестировать. И возможно, что я откажусь от идеи использования БД для задач алготрейдинга. Но точно то, что базовые знания SQL будут для меня, как начинающего изучать пайтон, абсолютно не лишними.
Так или иначе, но по итогу создания своей первой консольной программы для меня сформировалось 2 задачи по изучению материала: а) освоить создание удобного GUI интерфейса с графическими элементами управления (окна, кнопки, меню, и т.д.) и б) попробовать внедрить и использовать в работе базу данных, для начала это будет SQLite. Уверен, что все это крайне полезные компоненты для создания собственных инструментов алготрейдинга.
Тему backtrader из-за этих задач сейчас немного отодвигаю по времени, но 100% к ней, как одной из самых ключевых, я обязательно вернусь.
Ну и ближе к делу. В ходе знакомства с SQL и SQLlite мы создадим единую базу данных с котировками всех акций Московской биржи, полученных ранее с помощью программы Тахометр трейдера v.1.0.
Понятия SQL и SQLite
SQLite — это компактная встраиваемая реляционная база данных, которая обеспечивает локальное хранение данных в одном файле без необходимости установки отдельного сервера базы данных. SQLite поддерживает стандартный набор SQL запросов. SQLite широко используется в приложениях, где требуется легковесное и простое встраиваемое хранилище данных. SQLite является автономной БД без каких-либо зависимостей. SQLite не требует настройки и администрирования.
SQL (Structured Query Language) — это язык структурированных запросов, используемый для взаимодействия с базами данных. Он позволяет выполнять операции, такие как создание и изменение таблиц, вставку, обновление, удаление и выборку данных из таблиц, создание и удаление индексов, и многое другое. SQL является стандартным языком для работы с реляционными базами данных, такими как MySQL, PostgreSQL, SQLite, Microsoft SQL Server, и др.
БД, таблицы, связи, типы данных
База данных состоит из таблиц. Таблица имеет поля (колонки) и записи (строки). В реляционной базе данных таблицы связаны друг с другом с помощью ключевых полей, что обеспечивает структурированное хранение и доступ к данным.
- Первичный ключ (Primary Key) — это уникальный идентификатор для каждой записи в таблице. Он гарантирует, что каждая строка имеет уникальное значение и предоставляет способ быстрого доступа к конкретной записи в таблице.
- Внешний ключ (Foreign Key) в реляционной базе данных — это поле или набор полей в таблице, которые связаны с первичным ключом другой таблицы. Он устанавливает связь между двумя таблицами, позволяя ссылаться на записи в одной таблице из другой.
- Составной ключ (Composite Key) в реляционной базе данных — это ключ, состоящий из нескольких полей (столбцов) в таблице, которые вместе уникально идентифицируют каждую запись. В отличие от первичного ключа, который состоит из одного поля, составной ключ может содержать комбинацию нескольких полей для обеспечения уникальности данных.
Связи между таблицами отображаются в виде схемы базы данных, также известной как диаграмма «сущность — связь» (ERD, Entity Relationship Diagram).
В такой схеме может быть несколько типов связей:
- Связь «один-ко-многим» (one-to-many) означает, что одна запись в одной таблице связана с несколькими записями в другой таблице. Например, один автор может иметь много книг, что описывается отношением «один-ко-многим» между таблицами авторов и книг.
- Связь «один-к-одному» (one-to-one): Одна запись в одной таблице связана с одной записью в другой таблице.
- Связь «многие-ко-многим» (many-to-many): Множество записей в одной таблице связано с множеством записей в другой таблице через промежуточную таблицу.
- Саморекурсия (Self-Referencing): Таблица имеет отношение к самой себе. Пример: Таблица «Сотрудники» может содержать столбец «Руководитель», который ссылается на другую запись в той же таблице, указывая, кто является руководителем каждого сотрудника.
Типы данных в SQLite :
- NULL: указывает на отсутствие значения.
- INTEGER: представляет целое число, которое может быть положительным или отрицательным.
- REAL: представляет число с плавающей точкой.
- TEXT: это строка текста, заключенная в одинарные кавычки. Она сохраняется в кодировке базы данных (например UTF-8).
- BLOB: представляет бинарные данные, такие как изображения или файлы.
В SQLite тип данных BOOLEAN не поддерживается. Однако, можно использовать целочисленный тип данных INTEGER с ограничением CHECK, чтобы эмулировать поведение логического типа. Логические значения сохраняются как целые числа 0 (ложь) и 1 (истина).
SQLite распознает ключевые слова «TRUE» и «FALSE» начиная с версии 3.23.0 (2018-04-02), но эти ключевые слова на самом деле представляют собой просто альтернативные варианты написания целочисленных литералов 1 и 0 соответственно.
SQLite не имеет типа данных для хранения дат и/или времени. SQLite может хранить дату и время в виде значений TEXT, REAL или INTEGER:
- TEXT в виде строк ISO8601 («YYYY-MM-DD HH:MM:SS.SSS»).
- REAL, как Джулианские дни — количество дней, прошедших с полудня в Гринвиче 24 ноября 4714 года до н.э. согласно пролептическому григорианскому календарю. Это числовое представление дат и времени, где каждому дню присваивается уникальный номер. Это непрерывный подсчет дней, который позволяет легко вычислять прошедшее время между датами и временем.
- INTEGER как Unix Time, количество секунд с 1970-01-01 00:00:00 UTC.
Приложения могут хранить дату и время в любом из этих форматов и свободно конвертировать их между собой с помощью встроенных функций даты и времени .
Программа для просмотра БД SQLlite
Для дальнейшей работы с SQLlite и изучения SQL в качестве дополнительного инструмента мы будем использовать программу «DB Browser for SQLite» , скачать ее можно с официального сайта sqlitebrowser.org.
Создание базы данных и таблицы
Создать БД очень просто в программе DB Browser for SQLite, мы же рассмотрим вариант создания в программе на python.
import sqlite3
# Подключение к базе данных
conn = sqlite3.connect("sql_algo.db")
# Создание курсора
cur = conn.cursor()
# Создание таблицы
cur.execute(
"""CREATE TABLE IF NOT EXISTS stocks
(SECID text, LISTLEVEL integer, SECNAME text)"""
)
# Вставка строки данных
cur.execute("INSERT INTO stocks VALUES ('SBER',1,'Сбербанк России ПАО ао')")
# Сохранение изменений
conn.commit()
# Закрытие соединения
conn.close()Метод connect необходим, чтобы установить связь с базой данных. При выполнении команды connect файл sql_algo.db либо будет открыт, либо будет создан, если он не существует. В результате создается (или открывается) БД с именем sql_algo.db.
Далее создаем объект Cursor для взаимодействия с БД и выполнения SQL-запросов. Используем метод execute (выполнить), которому в качестве аргумента передаем строку с SQL-запросом. В частности создаем таблицу stocks, если она не существует, указываем список и название полей, тип данных и первичный ключ, далее добавляем первую запись с данными.
Для применения всех изменений в таблице(ах) БД используем commit(). В конце программы при завершении работы с БД необходимо закрыть соединение с помощью метода close().
Используя конструкцию with автоматически будет закрыто соединение с базой данных после выполнения блока кода. Это гарантирует, что ресурсы будут правильно освобождены, даже если произойдет исключение во время выполнения блока кода.
поэтому изменим наш код:
import sqlite3
# Подключение к базе данных
with sqlite3.connect("sql_algo.db") as conn:
cur = conn.cursor()
# Создание таблицы
cur.execute(
"""CREATE TABLE IF NOT EXISTS stocks
(SECID text PRIMARY KEY, LISTLEVEL integer, SECNAME text)"""
)
# Сохранение изменений
conn.commit()Таблица с информацией о всех акциях
Сначала удалим созданную ранее таблицу или всю базу данных. Далее возьмем за основу csv файл «list_tools.txt» из программы «Тахометр трейдера», в которой находится список всех акций Мосбиржи. В таблице предусмотрим все необходимые поля (27шт), что они означают мы писали в расшифровке.
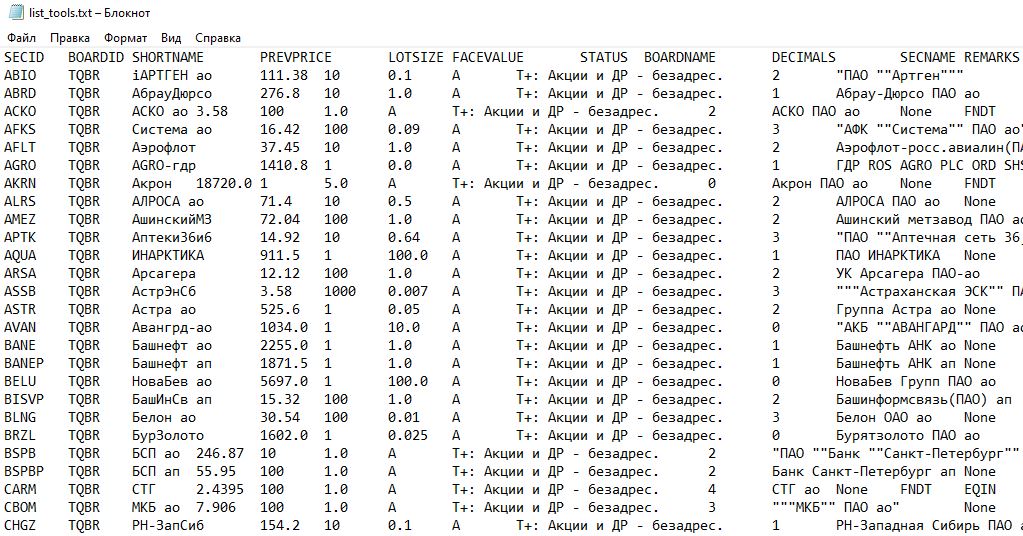
import csv
import sqlite3
# Подключение к базе данных
with sqlite3.connect("sql_algo.db") as conn:
cur = conn.cursor()
# Создание таблицы, если ее не существует
cur.execute("""
CREATE TABLE IF NOT EXISTS stocks (
SECID TEXT PRIMARY KEY,
BOARDID TEXT,
SHORTNAME TEXT,
PREVPRICE REAL,
LOTSIZE REAL,
FACEVALUE REAL,
STATUS TEXT,
BOARDNAME TEXT,
DECIMALS INTEGER,
SECNAME TEXT,
REMARKS TEXT,
MARKETCODE TEXT,
INSTRID TEXT,
SECTORID TEXT,
MINSTEP REAL,
PREVWAPRICE REAL,
FACEUNIT TEXT,
PREVDATE TEXT,
ISSUESIZE REAL,
ISIN TEXT,
LATNAME TEXT,
REGNUMBER TEXT,
PREVLEGALCLOSEPRICE REAL,
CURRENCYID TEXT,
SECTYPE TEXT,
LISTLEVEL INTEGER,
SETTLEDATE TEXT)
""")
# Открытие файла CSV и вставка выбранных данных в таблицу
with open("list_tools.txt", "r", encoding="utf-8") as file:
csv_reader = csv.reader(file, delimiter="\t")
next(csv_reader) # Пропускаем первую строку с названием колонок
for row in csv_reader:
cur.execute(
"""
INSERT OR IGNORE INTO stocks (SECID, BOARDID, SHORTNAME, PREVPRICE, LOTSIZE, FACEVALUE, STATUS, BOARDNAME, DECIMALS, SECNAME, REMARKS, MARKETCODE, INSTRID, SECTORID, MINSTEP, PREVWAPRICE, FACEUNIT, PREVDATE, ISSUESIZE, ISIN, LATNAME, REGNUMBER, PREVLEGALCLOSEPRICE, CURRENCYID, SECTYPE, LISTLEVEL, SETTLEDATE)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
""",
row,
)
# Сохранение изменений в базе данных
conn.commit()Здесь функция next(reader) используется для получения следующей строки после текущей позиции чтения в файле. По умолчанию, если вы не указали начальную позицию чтения, то первый вызов next(reader) начнет чтение с первой строки файла. У нас первые строки в файлах — заголовки, поэтому и делаем переход на следующую строку.
В SQL запросе используются знаки вопроса «?» для подстановки значений из кортежа row. Как пишут гуру это делает код более безопасным, так как предотвращает SQL-инъекции. Технически конечно можно использовать запрос и в виде f- строки, но так будет длиннее перечислять все 27 элементов: «{row[0]}» и т.д.
try для обработки исключений в случае возникновения ошибки, например при повторной попытке добавить запись с идентичным наименованием акции в поле с первичным ключом. Однако мы использовали INSERT OR IGNORE — это выражение SQL, которое позволяет выполнить операцию вставки в таблицу, игнорируя любые попытки записи строк, которые вызовут конфликт с уникальными ключами или ограничениями целостности данных. Если вставляемая строка вызывает конфликт с уникальным ключом или ограничением целостности, то эта операция вставки будет проигнорирована, и запись не будет выполнена.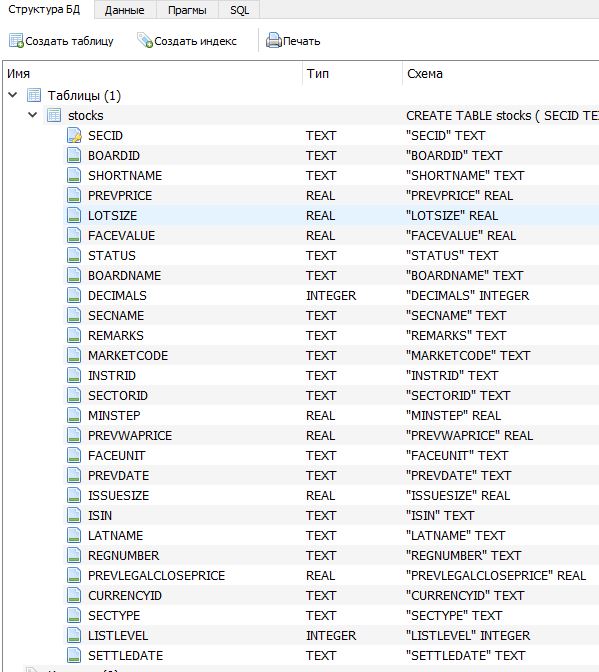
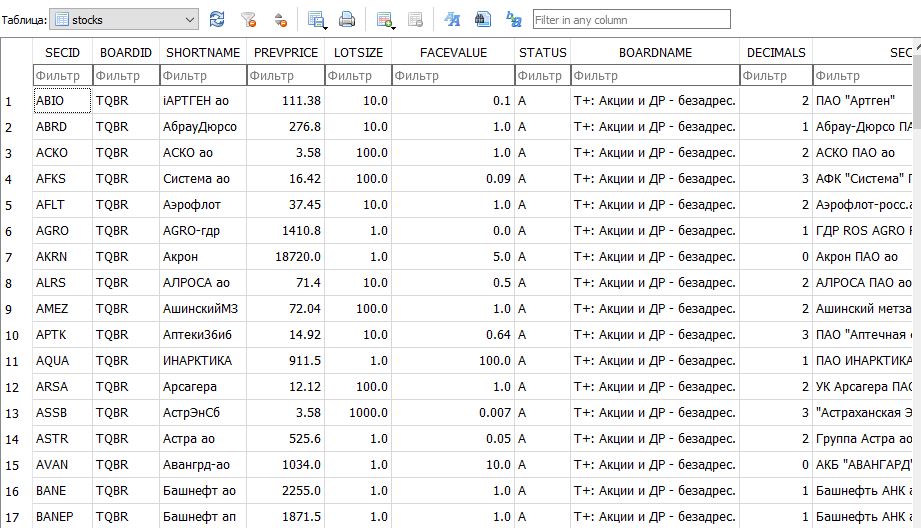
Таблицы с котировками по всем акциям Мосбиржи
Реляционная база данных — это тип базы данных, который организует данные в виде набора таблиц с отношениями между ними, т.е. связями между таблицами, о которых было сказано в самом начале статьи. И первая идея была такая, чтобы создать одну таблицу для хранения всех OHCLV по всем акциям, предусмотреть в ней поле SECID в качестве внешнего ключа и связать две таблицами (уже созданную stocks и новую таблицу с котировками) связью one-to-many. Однако статистика о скачанных данных, которая получена с помощью специального скрипта (об этом я писал в ТГ канале «Алготрейдинг на Python») дает информацию, что в таблице с котировками будет 116 миллионов строк. Для одной таблицы SQLlite я думаю это многовато и запросы к такой таблице будут более длительные, чем к отдельной таблице с котировками для отдельной акции. Кроме того БД из двух таблиц получится больше за счет лишнего повторения (116млн раз) наименований акций. Второй момент принятия решения — использовать только минутки или все скачанные таймфреймы (1, 10, 60 мин и дневки). Время покажет как лучше, но сейчас сделаем таблицы с котировками для каждого таймфрейма и акции отдельно. Если впоследствии нужно будет оставить только один таймфрейм, то лишние таблицы можно просто удалить. Единственный условный минус в нашей БД — между таблицей stocks и таблицами с котировками не установить связи, это немного бессмысленно для таблицы SBER вводить поле в котором все записи будут равны SBER.
Итак, приступаем и создаём в БД таблицы для хранения котировок OHCLV для каждой акции в отдельности. Названия таблиц будут соответствовать названию акции — значению поля SECID + таймфрейм. Например для Сбера будут созданы таблицы: SBER-1, SBER-10, SBER-60, SBER-D. Далее берем соответствующие csv файлы и загоняем информацию из них в таблицы БД.
import csv
import os.path
import sqlite3
import time
from datetime import datetime
start_time = time.time() # Засекаем время начала выполнения программы
print(
"Эта программа создаст (или обновит ранее созданную) базу данных SQLite с котировками всех акций Мосбиржи. Программа должна находиться рядом с каталогом 'historical_data', содержащим файлы с котировками акций."
)
folder_path = "historical_data" # папка с файлами исторических данных
# Формируем путь к файлу базы данных в этом каталоге
db_file_path = os.path.join("sql_algo.db")
# Подключение к базе данных
with sqlite3.connect(db_file_path) as conn:
cur = conn.cursor()
print("Подключение к базе данных SQLite прошло успешно")
# Создание таблицы stocks, если ее не существует
cur.execute(
"""
CREATE TABLE IF NOT EXISTS stocks (
SECID TEXT PRIMARY KEY,
BOARDID TEXT,
SHORTNAME TEXT,
PREVPRICE REAL,
LOTSIZE REAL,
FACEVALUE REAL,
STATUS TEXT,
BOARDNAME TEXT,
DECIMALS INTEGER,
SECNAME TEXT,
REMARKS TEXT,
MARKETCODE TEXT,
INSTRID TEXT,
SECTORID TEXT,
MINSTEP REAL,
PREVWAPRICE REAL,
FACEUNIT TEXT,
PREVDATE TEXT,
ISSUESIZE REAL,
ISIN TEXT,
LATNAME TEXT,
REGNUMBER TEXT,
PREVLEGALCLOSEPRICE REAL,
CURRENCYID TEXT,
SECTYPE TEXT,
LISTLEVEL INTEGER,
SETTLEDATE TEXT)
"""
)
# Открытие файла CSV со списком акций и вставка выбранных данных в таблицу
file_list_tools_path = os.path.join(folder_path, "list_tools.txt")
with open(file_list_tools_path, "r", encoding="utf-8") as file:
csv_reader = csv.reader(file, delimiter="\t")
next(csv_reader) # Пропускаем первую строку с названием колонок
for row in csv_reader:
cur.execute(
"""
INSERT OR IGNORE INTO stocks (SECID, BOARDID, SHORTNAME, PREVPRICE, LOTSIZE, FACEVALUE, STATUS, BOARDNAME, DECIMALS, SECNAME, REMARKS, MARKETCODE, INSTRID, SECTORID, MINSTEP, PREVWAPRICE, FACEUNIT, PREVDATE, ISSUESIZE, ISIN, LATNAME, REGNUMBER, PREVLEGALCLOSEPRICE, CURRENCYID, SECTYPE, LISTLEVEL, SETTLEDATE)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
""",
row,
)
print("Таблица stocks с информацией по акциям создана/обновлена")
# -- ! создаем таблицы для котировок для всех SECID (акций)
# Получение всех уникальных значений поля SECID из таблицы stocks
cur.execute("SELECT SECID FROM stocks")
rezult_SECIDs = cur.fetchall()
# Динамическое создание таблиц
print("Работаем с таблицами котировок...")
for secid in rezult_SECIDs:
table_name = secid[0].replace(
"-", "_"
) # Название таблицы равно значению SECID + замена дефисов
table_name_period = [
table_name + "_D",
table_name + "_60",
table_name + "_10",
table_name + "_1",
]
for table_name in table_name_period:
cur.execute(
f"""CREATE TABLE IF NOT EXISTS {table_name}
(
start_time INTEGER PRIMARY KEY,
end_time INTEGER,
open_price REAL,
high_price REAL,
low_price REAL,
close_price REAL,
volume REAL,
trades REAL
)"""
)
# -- ! в цикле создания таблиц для котировок наполняем их данными
file_name = f"{table_name.replace('_', '-')}.txt" # Создаем название файла с данными
file_path = os.path.join(folder_path, file_name)
# Проверяем существует ли файл в каталоге historical_data
if not os.path.exists(file_path):
print(f"Файл {file_path} не найден в каталоге historical_data")
else:
print(
f"Файл {file_path} в каталоге historical_data найден, обновляем таблицу {table_name}..."
)
with open(file_path, "r", encoding="utf-8") as file:
reader = csv.reader(file, delimiter="\t")
next(reader) # Пропускаем первую строку с заголовками
# Вставляем данные в таблицу
for row in reader:
# Преобразование в строке даты и времени open и close в Unix Time
unixtime_row = (
int(
time.mktime(
datetime.strptime(
row[0], "%Y-%m-%d %H:%M:%S"
).timetuple()
)
),
int(
time.mktime(
datetime.strptime(
row[1], "%Y-%m-%d %H:%M:%S"
).timetuple()
)
),
row[2],
row[3],
row[4],
row[5],
row[6],
row[7],
)
# Вставка данных в таблицу
cur.execute(
f"INSERT OR REPLASE INTO {table_name} VALUES (?,?,?,?,?,?,?,?)",
unixtime_row,
)
# Сохранение изменений в базе данных
conn.commit()
end_time = time.time() # Засекаем время окончания выполнения программы
execution_time = end_time - start_time # Вычисляем время выполнения программы
hours = int(execution_time // 3600) # Получаем часы
minutes = int((execution_time % 3600) // 60) # Получаем минуты
seconds = int(execution_time % 60) # Получаем секунды
print(
f"Программа выполнена за {hours} часов {minutes} минут {seconds} секунд"
) # Выводим время выполнения программы в терминалОператор
REPLACE в SQL используется для вставки новой строки в таблицу или обновления существующей строки, если строка с такими же значениями ключевых полей уже существует. Если строка с такими же значениями ключевых полей уже существует, то она заменяется новыми значениями, в противном случае новая строка добавляется в таблицу. Это также обеспечивает уникальность данных в таблице. У нас во всех таблицах поле start_time (begin) установлено в качестве первичного ключа и оно является уникальным.Время (поля start_time и end_time) из формата «2024-02-14 14:58:00» переведено в UNIX-время (целочисленный тип данных). С одной стороны это снизит объем базы данных, с другой стороны хранение даты и времени в формате Unix-времени позволяет выполнять более эффективные операции сравнения и сортировки, так как это представление даты и времени как целого числа, представляющего количество секунд, прошедших с начала эпохи Unix. Также можно легко преобразовать Unix-время в удобочитаемый формат при помощи функции datetime.fromtimestamp() при извлечении данных из базы данных, или при выполнении запросов SQL.
Во время работы программы в каталоге рядом с файлом БД создался файл sql_algo.db-journal , который является журнальным файлом и используется базой данных SQLite для отслеживания изменений, которые еще не были полностью записаны в основной файл базы данных. Этот файл создается временно и удаляется после завершения операций записи.
Итак, чтобы воспользоваться этой программой скачайте ее дистрибутив для windows и сохраните в каталоге программы «Тахометр трейдера», рядом должен будет находиться каталог «historical_data». Можно запускать.
У меня программа проработала 48 минут 40 секунд. Уточню, что время зафиксировано на компьютере с ssd диском, а вот на hdd диске время скорее всего будет на порядок больше.
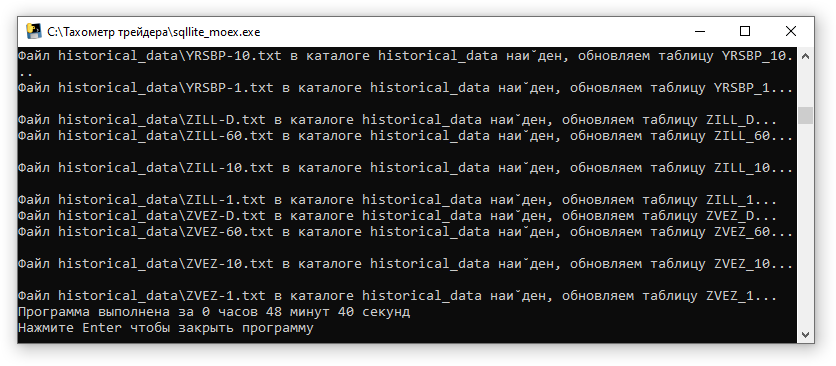
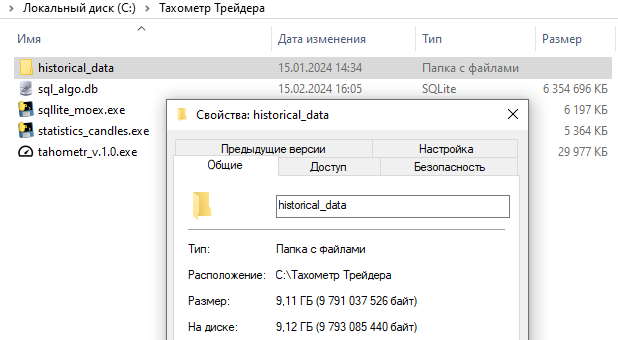
Объем базы данных составил 6,35Гб, тогда как объем файлов csv составляет 9,11Гб, т.е. на 30% меньше.
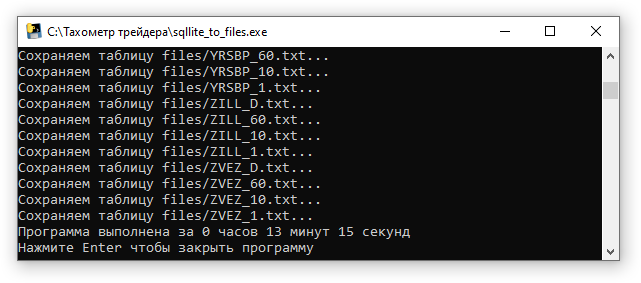
Ну и в заключении давайте сделаем обратную операцию: все таблицы созданной базы sql_algo.db сохраним в отдельных csv файлах с расширением txt для удобства их просмотра. Ниже простая программа, в ней даже время из unix формата обратно в «%Y-%m-%d %H:%M:%S» не переводится.
import os
import sqlite3
import time
import pandas as pd
start_time = time.time() # Засекаем время начала выполнения программы
print('Сохранение всех таблиц базы данных в файлы в каталоге "files"')
# Подключение к базе данных
with sqlite3.connect("sql_algo.db") as conn:
# Получение списка всех таблиц в базе данных
tables = pd.read_sql_query(
"SELECT name FROM sqlite_master WHERE type='table';", conn
)
# Создание каталога "files", если его еще нет
os.makedirs("files", exist_ok=True)
# Сохранение каждой таблицы в отдельный CSV файл с названиями полей
for table in tables["name"]:
print(f"Сохраняем таблицу files/{table}.txt...")
df = pd.read_sql_query(f"SELECT * FROM {table}", conn)
df.to_csv(f"files/{table}.txt", index=False, header=True, sep="\t")
end_time = time.time() # Засекаем время окончания выполнения программы
execution_time = end_time - start_time # Вычисляем время выполнения программы
hours = int(execution_time // 3600) # Получаем часы
minutes = int((execution_time % 3600) // 60) # Получаем минуты
seconds = int(execution_time % 60) # Получаем секунды
print(
f"Программа выполнена за {hours} часов {minutes} минут {seconds} секунд"
) # Выводим время выполнения программы в терминал
input("Нажмите Enter чтобы закрыть программу")Запрос («SELECT name FROM sqlite_master WHERE type=’table’;», conn ) используется для получения списка имен всех таблиц в базе данных SQLite.
SELECT name — указывает, что мы хотим выбрать только столбец «name» из результатов запроса. Это означает, что мы получим только имена таблиц.
FROM sqlite_master — указывает, что мы хотим выполнить запрос на таблице sqlite_master. Это встроенная системная таблица SQLite, которая содержит метаданные о базе данных, включая список всех таблиц.
WHERE type='table' — это условие, которое фильтрует результаты запроса, оставляя только те строки, где тип объекта равен ‘table’. Это гарантирует, что мы получаем только имена самих таблиц, а не другие объекты в базе данных.
Далее использован метод pd.read_sql_query из библиотеки pandas для чтения данных из базы данных SQL и преобразования их в DataFrame. Он принимает SQL запрос и соединение с базой данных в качестве параметров и возвращает DataFrame, содержащий результат запроса, в частности (f"SELECT * FROM {table}", conn) .
Этот запрос используется для извлечения всех данных из конкретной таблицы в базе данных SQLite.
f"SELECT * FROM {table}" — это строка запроса, в которой мы используем f-строку для подстановки имени таблицы. Здесь {table} заменяется на фактическое имя таблицы при выполнении запроса. Например, если имя таблицы равно «SBER_1», то строка запроса будет выглядеть как «SELECT * FROM SBER_1». conn — это объект соединения с базой данных SQLite, который передается в качестве параметра для выполнения запроса.
Время работы программы составило 13 минут.
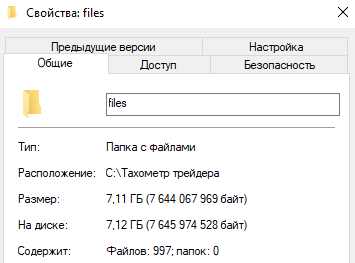
В результате были созданы файлы с котировками с разными таймфреймами для всех акций. Объем данных составил 7,1Гб вместо 9.1Гб первоначальных, скорее всего уменьшение объема произошло за счет сохранения времени в Unix формате.
На этом эксперимент свой заканчиваю, считаю его вполне успешным и интересным. В SQL сильно не стал погружаться, т.к. без практики все равно знания «улетучатся», однако общее понимание работы с БД и SQL запросами теперь есть.
SQLlite простая и удобная для настольных приложений БД, однако скорости записи в нее оставляют желать лучшего.
Изучая различные обзоры по БД я невольно получил общие сведения еще и о нереляционных базах, в которых не используется табличная схема строк и столбцов. При этом NoSQL базы данных очень гибкие и высокопроизводительные и ярким представителем является MongoDB. Возможно, что впоследствии очередь для практического знакомства дойдет и до нее.
И в заключении, что мне понравилось из методических материалов и что я мог бы рекомендовать для новичков:
- книга «SQL. Быстрое погружение — Уолтер Шилдс» и
- в прямом смысле супер конспект-шпаргалка на Хабре.







