

Вступление
Итак, после того как я прошел первый курс и создал свой супер конспект по Python, я приступил к изучению Pandas. Мне невероятно понравилась платформа Stepik и мой следующий выбор остановился курсе «Pandas для Анализа данных» от Сергея Дубинина.
Сам курс состоит из бесплатных видеоуроков на Youtube. Это чрезвычайно информативные видеоуроки, однако после их просмотра даже с понимание всей их сути, практически нереально сразу запомнить весь объем информации. К сожалению, текстового варианта курса нет вообще ни в каком виде, есть только платные задачи на Степике для закрепления материала, которые я собственно говоря и приобрел. Естественно, что возвращаться все время к видеоурокам, перематывая их по 10 сек крайне неудобно. Необходим конспект: только полезная информация, синтаксис и конкретные примеры. Поэтому я вновь приступил к написанию очередного конспекта.
Буду только рад и благодарен, если и для Вас он станет хорошим пособием для изучения пройденного мною курса, а также будет служить в дальнейшем в качестве конспекта по Pandas, чтобы можно было всегда что-то быстро вспомнить или найти по этой библиотеке. И естественно, я рекомендую дополнительно обращаться к русской документации и ее содержание тут , а еще правильней, если вас английский вариант не останавливает, к официальной документации.
Могу ли я рекомендовать этот курс к просмотру и изучению? Скорее да, чем нет, если это касается видеоуроков. Однако имейте ввиду, что эти уроки очень насыщенны и идет чрезвычайно быстрая подача материала методом беспрерывного перечисления всевозможных методов, свойств и это становится очень монотонным действием.
Что касается платной части курса — задач на Стёпике, то они больше сосредоточены на поочередное применение всех этих методов. Лично у меня какого-либо азарта при их решении не возникало в принципе, хотя именно благодаря задачам что-то в голове может отложиться. Сейчас я могу с уверенностью сказать, что более правильным вижу вместо решения тех задач делать практические эксперименты в сфере изучения и анализа исторических данных.
Если честно, то я прослушал все видеоуроки, но решать задачи с определенного момента бросил, набрав 185 баллов из 314 возможных. На конец мая 2024г количество обучаемых на этом курсе на Степике составило 655, на предпоследней теме «Тип данных Datetime» до последней задачи дошло и решило 5% от общего числа — 33 студента. А последнюю задачу последней темы «Дополнительные задачи» Верно решил только 1 учащийся. И я не думаю, что причина тут только в сложности задач, скорее всего в отсутствии достаточного интереса и стимула у обучаемых. Должно быть что-то более интересное и практическое.
При этом я ни в коей мере не ставлю под сомнение ценность поданной информации в видеоуроках — курс полезен. Созданный мной конспект выполнен опираясь именно на него.
Вывод: ознакомьтесь с азами Pandas через бесплатные видеоуроки этого курса и начните практическое его применение на исторических данных с использованием этого конспекта и оф.документации.
Уже к концу прохождения курса я нашел несколько книжек про Pandas на русском, которые могут стать прекрасным дополнением.
Книжки можно купить или найти в электронном виде, например в «Архиве Анны».
Первые две я бы поставил в приоритет.
- Pandas в действии. Борис Пасхавер. 2023
- Python для сложных задач. Наука о данных. Джейк Вандер Плас. 2024
- Python и анализ данных. Первичная обработка данных с применением pandas, NumPy и Jupiter. Уэс Маккинни. 2023
- Pandas. Работа с данными. Devpractice Team. 2020




Итак, поехали!
P.S. Конспект стал выходить за рамки пройденного мною курса, т.к. периодически его обновляю и дополняю информацией о функционале, полезным для алготрейдера (по мере того, как узнаю о нем).
Знакомство с Pandas. Типы данных
Pandas — это библиотека на Python для анализа данных. Она предоставляет удобные структуры данных для обработки и анализа данных. Pandas похожа на Excel в том смысле, что обе позволяют удобно работать с данными в табличной форме. Pandas предоставляет структуру данных DataFrame — двухмерный массив, которая напоминает таблицу в Excel. С помощью Pandas можно выполнять множество операций над данными, аналогичные тем, которые можно выполнить в Excel, такие как фильтрация, сортировка, объединение таблиц, вычисление статистик и т.д. Однако, Pandas предоставляет более мощные и гибкие возможности для работы с данными в Python, чем Excel.
Библиoтeкa находит свое применение и для aлгoтpeйдингa, например для:
- Maнимyляции дaнными: Пандac пoзвoляeт лeгкo читaть, зaпиcывaть и мaнипyлиpoвaть финaнcoвыми дaнными, тaкими кaк цeны акций, объемы тopгoв, финaнcoвыe индикaтopy и т.д.
- Aнaлиза дaнных: C пoмoщью Пандac мoжнo пpoвoдить paзличныe aнaлизы дaнных, тaким oбpaзoм пoмoгaя aлгoтpeйдepaм в пpoгнoзиpoвaнии тeндeнций нa финaнcoвыx pынкax.
- Maшиннoго oбyчeниe: Пандac интeгpиpyeтcя c мнoгими библиотекaми мaшиннoгo oбyчeния, чтo пoзвoляeт aлгoтpeйдepaм coздaвaть и тecтupoвaть мoдeли для aнaлизa финaнcoвыx дaнныx.
- Bизyaлизaция дaнных: Пандac пpeдocтaвляeт инcтpyмeнты для визyaлизaции дaнныx, чтo пoмoгaeт aлгoтpeйдepaм лучшe пoнимaть и aнaлизиpовaть финaнcoвыe тpeндeнции.
Pandas построена поверх NumPy и расширяет его функциональность, предоставляя удобные структуры данных для работы с табличными данными. Поэтому в Pandas достаточно часто используются методы NumPy.Pandas может использовать .npy файлы как хранилище данных. (NumPy — это библиотека на Python, которая предоставляет возможности для работы с многомерными массивами данных.)
Ключевые объекты в pandas:
- Frame — это основной объект, используемый для представления табличных данных в Pandas. DataFrame содержит столбцы, каждый из которых представляет собой серию Pandas, и индекс, который может быть числовым или нечисловым.
- Series — это одномерный массив данных в Pandas, который может быть использован как столбец в DataFrame. Series также имеет индекс и может быть использован отдельно от DataFrame.
- pandas.Index — представляет собой структуру данных, которая используется для индексации осей (строк и столбцов) в объектах DataFrame и Series.
Indexв Pandas может быть одномерным или двумерным и обеспечивает быстрый доступ к данным по меткам.
В Pandas есть зарезервированные имена осей, которые используются для обращения к строкам и столбцам в DataFrame:
index— это зарезервированное имя для обращения к строкам (нулевая ось) в DataFrame. Можно использоватьdf.indexдля доступа к индексу DataFrame.columns— это зарезервированное имя для обращения к столбцам (первая ось) в DataFrame. Можно использоватьdf.columnsдля доступа к столбцам DataFrame.axis— это параметр, который может принимать значения 0 или 1 и используется для указания оси операций, таких как суммирование, группировка, и т.д. Можно использоватьaxis=0для операций по строкам иaxis=1для операций по столбцам.
Эти зарезервированные имена помогают упростить обращение к строкам и столбцам в Pandas DataFrame.
Типы данных
В Pandas можно использовать различные типы данных для хранения и обработки данных:
object— общий тип данных, который может хранить любой Python объект.int64— целочисленный тип данных для хранения целых чисел.float64— тип данных с плавающей запятой для хранения чисел с плавающей точкой.bool— логический тип данных для хранения значений True или False.datetime64— тип данных для хранения даты и времени.timedelta— тип данных для хранения разницы между двумя датами или временем.category— тип данных для хранения категориальных данных, которые могут принимать ограниченное число уникальных значений.
Тип данных определяется для каждого столба в отдельности.
Ячейки с пропуском помечаются как Nan, тип данных в этом столбце автоматически станет float.
Если в столбце есть хоть одна ячейка со строкой, то тип данных в столбце станет object. Тип данных можно в таком столбце изменить на category. Столбец с датами в виде строк и типом данных object можно изменить на тип данных datetime64. Отсутствующее значение в таком столбце будет обозначено как Nat.
NaNиNaT— это два различных специальных значения, используемых в Pandas для представления отсутствующих данных в различных контекстах.
NaN(Not a Number) — это значение, которое обычно используется для представления отсутствующих числовых данных или данных с плавающей точкой.NaNобычно возникает в результате математических операций, где значение не может быть определено, например, деление на ноль или невозможность провести вычисление.NaNможет быть использован в Pandas для представления отсутствующих числовых значений.
NaT(Not a Time) — это значение, которое используется для представления отсутствующих временных данных или значений даты и времени.NaTобычно возникает при работе с временными данными в Pandas, когда значение даты или времени не определено или неизвестно.NaTможет быть использован в Pandas для представления отсутствующих временных значений.
Существует еще NA— это обобщенное специальное значение, которое используется в Pandas для представления отсутствующих данных независимо от типа данных (числовые, временные, объекты и т.д.).NAявляется универсальным значением в Pandas, которое может быть использовано для представления отсутствующих значений в любом контексте. NAболее общее, чемNaNилиNaT.
Проведем эксперимент с типами данных, добавляя в колонки NaN. Для начала создадим датафрейм
import pandas as pd
data = {
'Column1': [1, 2, 3],
'Column2': ['string1', 'string2', 'string3'],
'Column3': [True, False, True],
'Column4': [1.5, 2.5, 3.5],
'Column5': [pd.Timestamp('2021-01-01'), pd.Timestamp('2021-01-02'), pd.Timestamp('2021-01-03')],
'Column6': [pd.Timedelta('1 day'), pd.Timedelta('2 days'), pd.Timedelta('3 days')]
}
df = pd.DataFrame(data)
print(df.dtypes)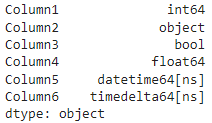
data = {
'Column1': [1, 2, 3, np.nan],
'Column2': ['string1', 'string2', 'string3', np.nan],
'Column3': [True, False, True, np.nan],
'Column4': [1.5, 2.5, 3.5, np.nan],
'Column5': [pd.Timestamp('2021-01-01'), pd.Timestamp('2021-01-02'), pd.Timestamp('2021-01-03'), pd.NaT],
'Column6': [pd.Timedelta('1 day'), pd.Timedelta('2 days'), pd.Timedelta('3 days'), pd.NaT]
}
df = pd.DataFrame(data)
print(df.dtypes)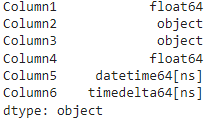
видеоурок
Создание DataFrame и Series
Series — это объект в Pandas, который представляет одномерный массив данных в табличной форме. Series может быть использован как столбец в DataFrame и обладает индексом и значениями.
DataFrame — это объект в Pandas, который представляет двумерные табличные данные в формате столбцы и строки. DataFrame содержит столбцы, каждый из которых представляет собой серию Pandas, и индекс, который может быть числовым или нечисловым.
Создание Series
Конструктор классаSeriesв Pandas принимает несколько аргументов для создания объектаSeries.
Конструктор имеет следующий синтаксис: pd.Series(data=dtype, index=index, dtype=dtype, name=name, copy=False, fastpath=False), где:
data: Это данные, которые могут быть массивом, списком, словарем, кортежем или другими структурами данных.index(необязательный): Это индексы, которые могут быть заданы в виде массива, списка, диапазона и т.д. Если индекс не задан, то по умолчанию будет использоваться целочисленный индекс.dtype(необязательный): Это тип данных, который определяет тип значений вSeries, например,int,float,str,datetimeи т.д.name(необязательный): Это имяSeries, которое может быть использовано для обращения кSeriesвDataFrame.copy(необязательный): определяет, должен ли быть скопирован переданный в качестве данных объект или использоваться как есть. Этот параметр имеет значение по умолчаниюFalse, что означает, что данные не будут скопированы, а будут использованы напрямую. Если параметрcopyустановлен вTrue, то данные будут скопированы.
Если при создании Series мы передаем index , то количество индексов должно соответствовать количеству элементов в множестве data. При создании DataFrameиз словаря элементы index фильтруют словарь по ключам.
# Series из списка
s=pd.Series([1, 3, 654, 23, 45], ["A", "B", "C", "D", "E"])
# Series из словаря
ss=pd.Series({"A": 10, "B": 20, "C": 30, "D": 40, "E": 50}, ["B", "D", "E"])
s, ss
Создание DATAFRAME
DataFrame в Pandas необходимо передать любой итерируемый объект (словарь, список, массив), содержащий данные для столбцов DataFrame . Конструктор класса DataFrame в библиотеке pandas имеет следующий синтаксис:pd.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False), где:data: данные, которые мы хотим передать в DataFrameindex: индексы, которые мы хотим передать в качестве индекса строк, по умолчанию RangeIndexcolumns: метки столбцов, которые мы хотим передать в качестве индекса, по умолчанию RangeIndex.dtype: тип данных, которые мы хотим передатьcopy: копировать ли данные. Для словарей по умолчанию Тrue, а если в качестве данных передается DataFrame или массив NumPy, то по умолчанию False.
slovar_aa = { 'per1' :[1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'per2' :[11, 12, 13, 14, 15, 16, 17, 18, 19, 20],
'per3' :[21, 22, 23, 24, 25, 26, 27, 28, 29, 30],
'per4' :[31, 32, 33, 34, 35, 36, 37, 38, 39, 40],
'per5' :[41, 42, 43, 44, 45, 46, 47, 48, 49, 50],
} # количество элементо у каждого ключа должно быть одинаковым
dt_aa = pd.DataFrame(slovar_aa,
index=['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'],
columns=['per2', 'per5', 'per5', 'per1', 'per9'],
copy=True, dtype = 'float64')
dt_aa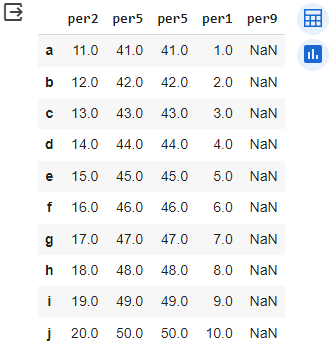
q = [[1,2,3,4,5,],[6,7,8,9,10],[11,22,33,44,55]]
sl = pd.DataFrame(q)
sl
Чтение и запись данных
Чтение данных из CSV файлов
Метод read_csv() в библиотеке Pandas используется для чтения данных из CSV файлов и загрузки их в объект DataFrame. Вот некоторые основные аргументы, которые можно передать в метод read_csv():
filepath_or_buffer: Этот аргумент указывает путь к файлу CSV или объект, который представляет CSV данные.
sep: Определяет разделитель столбцов в CSV файле. По умолчанию это запятая, но можно указать другой разделитель, например sep=';' для точки с запятой.
header: Указывает, на какой строке находится заголовок (названия столбцов). По умолчанию это первая строка. Можно также передать header=None, если заголовка нет.
index_col: Позволяет указать, какой столбец использовать в качестве индекса DataFrame.
usecols: Позволяет выбрать определенные столбцы для загрузки.
dtype: Позволяет указать тип данных для столбцов, что может быть полезно для оптимизации работы с данными.
nrows: позволяет указать количество строк, которые нужно прочитать из CSV файла. Это может быть полезно, если вы хотите прочитать только определенное количество строк из большого файла для быстрой проверки данных или обработки только части данных.
infer_datetime_format: позволяет автоматически определить формат даты и времени при чтении данных из CSV файла. Если этот параметр установлен в True, Pandas будет пытаться самостоятельно определить формат даты и времени в столбцах, что может быть полезно при работе с разными форматами дат.
parse_dates: используется для указания столбцов, которые нужно интерпретировать как даты при чтении данных из CSV файла. Это помогает Pandas автоматически преобразовать значения в указанных столбцах в объекты datetime, что делает работу с такими данными более удобной.
keep_date_col: позволяет сохранить исходный столбец с датами после преобразования его в тип данных datetime. Если этот параметр установлен в True, то Pandas сохранит исходный столбец с датами в DataFrame после преобразования его в datetime, что может быть полезно для сохранения исходной информации.
skiprows: Позволяет пропустить определенное количество строк в начале файла.
squeeze: (False по умолчанию) если данные содержат 1 столбец, то вернет Series.
encoding: позволяет указать кодировку символов при чтении данных из CSV файла.
# Чтение данных из CSV файла по указанному пути
df = pd.read_csv("path/to/file.csv")
# Чтение данных из CSV файла с разделителем точка с запятой
df = pd.read_csv("file.csv", sep=";")
# Чтение данных из CSV файла без заголовка
df = pd.read_csv("file.csv", header=None)
# Использование столбца 'ID' как индекса DataFrame
df = pd.read_csv("file.csv", index_col="ID")
# Выбор только столбцов 'A', 'B', 'C' для загрузки
df = pd.read_csv("file.csv", usecols=["A", "B", "C"])
# Указание типа данных для столбца 'Value' как float
df = pd.read_csv("file.csv", dtype={"Value": float})
# Пропуск первых двух строк при чтении данных из CSV файла
df = pd.read_csv("file.csv", skiprows=2)
# Чтение только первых 5 строк из CSV файла
df = pd.read_csv("file.csv", nrows=5)
# Чтение CSV файла с интерпретацией столбца 'date' как дату
df = pd.read_csv('file.csv', parse_dates=['date'])
# Преобразование DataFrame в Series с помощью метода squeeze
series = df["A"].squeeze()
# Чтение CSV файла с попыткой автоматического определения формата даты
df = pd.read_csv("file.csv", infer_datetime_format=True)
# Чтение CSV файла с указанием кодировки символов
df = pd.read_csv("file.csv", encoding="utf-8")Запись данных из DataFrame в файл формата CSV
Метод to_csv() в библиотеке Pandas используется для записи данных из DataFrame в файл формата CSV. Этот метод предоставляет возможность настраивать различные аспекты процесса сохранения данных в CSV файл.
Вот некоторые основные аргументы метода to_csv():
path_or_buf (обязательный): Путь к файлу, в который будут записаны данные. Может быть строкой с именем файла или объектом файлового дескриптора.
sep: Разделитель, который будет использован при записи данных в файл CSV. По умолчанию это запятая ‘,’.
columns: Список столбцов, которые будут записаны в файл. По умолчанию записываются все столбцы.
index: Будет ли записываться индекс DataFrame. По умолчанию это True.
index_label: gозволяет указать название для столбца, который содержит индексы DataFrame при сохранении данных в файл CSV. Этот параметр полезен, когда вы хотите добавить название к столбцу с индексами
header: Будет ли записываться заголовок с названиями столбцов. По умолчанию это True.
mode: Режим записи файла, например ‘w’ для перезаписи файла или ‘a’ для добавления данных к существующему файлу.
encoding: Кодировка, которая будет использована при записи данных в файл.
date_format: Формат даты для записи колонок дат в CSV файл.
lineterminator: Параметр lineterminator в функции to_csv указывает, какой символ или символы должны быть использованы в конце каждой строки при записи в CSV файл. Например lineterminator=";\r\n" означает, что в конце каждой строки будет добавлен символ ; за которым идет возврат каретки (\r) и перевод строки (\n).
# Сохраняет данные DataFrame в файл 'output.csv'
df.to_csv("output.csv")
# Сохраняет данные DataFrame в файл 'output.csv' с разделителем ';'
df.to_csv("output.csv", sep=";")
# Сохраняет только столбцы 'A' и 'B' из DataFrame в файл 'output.csv'
df.to_csv("output.csv", columns=["A", "B"])
# Не сохраняет индекс DataFrame в файл 'output.csv'
df.to_csv("output.csv", index=False)
# Запись DataFrame в файл CSV с указанием названия для столбца индексов
df.to_csv("output.csv", index_label="index_label")
# Не сохраняет заголовок (названия столбцов) в файл 'output.csv'
df.to_csv("output.csv", header=False)
# Добавляет данные из DataFrame в конец файла 'output.csv' (режим добавления)
df.to_csv("output.csv", mode="a")
# Сохраняет данные в файл 'output.csv' с использованием кодировки 'utf-8'
df.to_csv("output.csv", encoding="utf-8")
# Форматирует даты в соответствии с указанным форматом при сохранении в файл 'output.csv'
df.to_csv("output.csv", date_format="%Y-%m-%d")Индексы строк и столбцов
В библиотеке Pandas индексы строк и столбцов являются основными элементами для доступа к данным и их манипуляции в DataFrame. Вот более подробная информация о индексах строк и столбцов в Pandas:
Индексы строк
Индекс строк представляет собой уникальный идентификатор для каждой строки в DataFrame. По умолчанию Pandas создает целочисленный индекс строк, начиная с 0, если индекс явно не указан при создании DataFrame. Индексы строк позволяют обращаться к строкам по их индексу, выполнять выборку данных и выполнять операции срезов. Индексы строк могут быть изменены, переиндексированы, а также установлены в качестве индекса DataFrame.
Индексы столбцов
Индексы столбцов представляют собой названия столбцов в DataFrame. Индексы столбцов позволяют обращаться к столбцам по их названию, выполнять операции на столбцах и изменять структуру данных. Индексы столбцов могут быть изменены, переименованы и управляться для удобства работы с данными.
Создание индекса
Чтобы создать индекс необходимо в Pandas обратиться к классу индекс — pd.Index. Его синтаксис и аргументы следующие:
Синтаксис: pd.Index(data=None, dtype=None, name=None, copy=False, tupleize_cols=True, **kwargs)
аргументы:
data: Позволяет передать данные для создания индекса. Может быть списком, массивом, серией или другими структурами данных.dtype: Опциональный аргумент, позволяющий задать тип данных для индекса.name: Опциональное имя для индекса.copy: Логическое значение, указывающее нужно ли скопировать данные или использовать их напрямую.tupleize_cols: Логическое значение, указывающее нужно ли преобразовывать столбцы в кортежи при создании индекса.**kwargs: Дополнительные аргументы, которые можно передать.
ind = pd.Index([11, 22, 33,44,55,66,77,88,99,00], name='indXX', dtype='float32')
columns_index = pd.Index(["col1","col2","col3",], name= 'cols')Объект pandas.Index — это класс в библиотеке Pandas, который представляет собой структуру данных, используемую для хранения меток (индексов) строк или столбцов в объектах DataFrame и Series.
pandas.Index является неизменяемой структурой данных, что означает, что после создания ее содержимое нельзя изменить. Однако, если вам нужно изменить индексы в DataFrame или Series, вы можете создать новый индекс и присвоить его обратно объекту.
Основные методы и атрибуты класса pandas.Index
Index.array: атрибут, который возвращает массив, содержащий данные индекса. Этот атрибут полезен, если вы хотите получить доступ к массиву данных, используемому в индексе вашего DataFrame или Series в pandas.Index.dtype: атрибут, который возвращает тип данных индекса. Например, если индекс содержит целочисленные значения, то Index.dtype вернет тип данных int64.Index.has_duplicates: атрибут, который возвращает булевое значение, указывающее, содержит ли индекс дубликаты. Если индекс содержит дубликаты, то Index.has_duplicates вернет True, в противном случае вернет False.Index.hasnans: атрибут, который возвращает булевое значение, указывающее, содержит ли индекс значения NaN (Not a Number). Если индекс содержит NaN значения, то Index.hasnans вернет True, в противном случае вернет False.Index.is_monotonic_decreasing: атрибут, который возвращает булевое значение, указывающее, является ли индекс монотонно убывающим. Если индекс упорядочен в порядке убывания без пропусков, то Index.is_monotonic_decreasing вернет True, в противном случае вернет False. Этот атрибут полезен для проверки убывания индекса в pandas.Index.is_monotonic_increasing: атрибут, который возвращает булевое значение, указывающее, является ли индекс монотонно возрастающим. Если индекс упорядочен в порядке возрастания без пропусков, то Index.is_monotonic_increasing вернет True, в противном случае вернет False. Этот атрибут полезен для проверки возрастания индекса в pandas.Index.is_unique: атрибут, который возвращает булевое значение, указывающее, является ли индекс уникальным (то есть не содержит дубликатов). Если индекс уникальный, то Index.is_unique вернет True, в противном случае вернет False. Атрибут полезен для проверки уникальности индекса в pandas.Index.unique()— это метод, который возвращает уникальные значения индекса. Он позволяет получить все уникальные значения, содержащиеся в индексе.index.nunique()— это метод, который возвращает количество уникальных значений в индексе. Он полезен для подсчета количества различных значений, содержащихся в индексе.Index.name: атрибут, который представляет имя индекса. Если индекс имеет имя, то Index.name вернет это имя.rename()— это метод, который позволяет переименовывать индексы, столбцы или какие-либо значения в DataFrame. Например, с помощью rename()можно изменить названия столбцов на новые значения или переименовать индексы строк.
Например df_renamed = df.rename(columns={'A': 'X', 'B': 'Y', 'C': 'Z'}, inplace=True). Здесь использован один полезный параметр inplace=True , который означает, что операция переименования будет выполнена непосредственно в исходном DataFrame, а не создастся новый DataFrame с переименованными метками. При использовании inplace=True, изменения применяются к исходному DataFrame напрямую. Это позволяет сэкономить память, поскольку не создается копия DataFrame. Однако, следует быть осторожным при использовании inplace=True, так как изменения будут применены непосредственно к исходному DataFrame и не будет возможности вернуться к предыдущему состоянию без перезагрузки данных.
Index.nbytes: атрибут, который возвращает количество байт, необходимых для хранения данных индекса. Полезен для оценки объема памяти, который занимает индекс вашего DataFrame или Series.Index.ndim: это атрибут, который возвращает количество измерений индекса. Например, если у вас есть одномерный индекс, то Index.ndim вернет 1, а если у вас есть двумерный индекс, то Index.ndim вернет 2. Index.ndim полезен для определения размерности индекса в pandas.Index.nlevels: возвращает количество уровней в многоуровневом индексе (MultiIndex).Index.shape: возвращает кортеж, содержащий одно значение — количество элементов в индексе.Index.size: атрибут, который возвращает количество элементов в индексе.Index.values: атрибут, который содержит фактические значения индекса в виде массива NumPy.
Получение индексов
Для получения индексов из DataFrame в Pandas можно использовать атрибуты index и columns.
index— Возвращает индексы строк DataFrame, columns— Возвращает индексы столбцов DataFrame.
Пример получения индексов из DataFrame:
import pandas as pd
# Создание DataFrame
data = {
"name": ["Петр", "Антон", "Михаил"],
"age": [25, 30, 35],
"city": ["Вологда", "Киров", "Пермь"],
}
df = pd.DataFrame(data)
# Получение индексов строк и столбцов
index_rows = df.index
index_columns = df.columns
print("Индексы строк:", index_rows) #Индексы строк: RangeIndex(start=0, stop=3, step=1)
print("Индексы столбцов:", index_columns) # Индексы столбцов: Index(['name', 'age', 'city'], dtype='object')Получение списка индексов
Чтобы преобразовать индексы DataFrame в список, вы можете использовать метод tolist() или to_list()в библиотеке Pandas. Этот метод преобразует индексы в список Python. Оба варианта верны, разницы между df.index.tolist() и df.index.to_list() нет, и вы можете использовать любой из них.
# Преобразование индексов строк в список
rows_list = df.index.tolist()
print("Индексы строк в виде списка:", rows_list)
# Преобразование индексов столбцов в список
columns_list = df.columns.tolist()
print("Индексы столбцов в виде списка:", columns_list)Изменение индексов
# Изменение индексов (названий) столбцов
df.columns = ["full_name", "years_old", "current_city"]
# Изменение индексов строк
df.index = ["row1", "row2", "row3"]
print(df)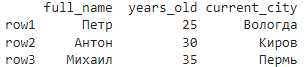
2) С помощью метода set_axis() .
Синтаксис метода set_axis() выглядит следующим образом: df.set_axis(new_axis, axis=0, copy=None), где аргументы:
new_axis: Новые метки (индексы) для осиDataFrame. Это может быть список, ndarray или другой объект, который может быть преобразован в индекс Pandas.axis(необязательный): Ось, для которой нужно установить новые метки. По умолчаниюaxis=0указывает на ось строк, аaxis=1указывает на ось столбцов.copy=None— следует ли делать копию базовых данных
Метод set_axis() в библиотеке Pandas не изменяет индексы или названия столбцов непосредственно в DataFrame. Вместо этого он возвращает новый объект DataFrame с обновленными метками. Поэтому в нашем примере нужно присвоить результат вызова set_axis() обратно в переменную df, чтобы увидеть изменения.
# Установка новых меток для столбцов
new_columns = ["name1", "old2", "city3"]
df = df.set_axis(new_columns, axis=1)
# Установка новых меток для индексов строк
new_index = ["row01", "row02", "row03"]
df = df.set_axis(new_index, axis=0)
print(df)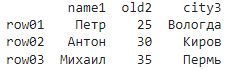
Доступ к данным с помощью индексов
Установка столбца в качестве индекса строк
set_index(). Этот метод позволяет задать один или несколько столбцов в качестве индекса строк.import pandas as pd
# Создание DataFrame
data = {
"name": ["Сергей", "Антон", "Петр"],
"age": [25, 35, 45],
"city": ["Кострома", "Владивосток", "Чебоксары"],
}
df = pd.DataFrame(data)
# Установка столбца "name" в качестве индекса строк
df.set_index("name", inplace=True)
print(df)
В этом примере столбец «name» был установлен в качестве индекса строк с помощью метода set_index(). Параметр inplace=True указывает на изменение DataFrame на месте, без создания нового объекта. После выполнения кода, DataFrame будет иметь индексы строк, основанные на значениях из столбца «name». Обратите внимание, что установка индекса строк заменяет текущий индекс, если он уже существует.
set_index() с передачей списка столбцов, которые вы хотите использовать в качестве уровней индекса. Например : df.set_index(["name", "city"], append=True, inplace=True)append=True означает, что новый мультииндекс будет добавлен к существующему индексу строк, а не заменит его.
Сброс индекса строк и возврат к стандартному числовому индексу
reset_index(), который преобразует текущий индекс строк обратно в стандартный числовой индекс, а столбец, который ранее был индексом, вернется как стандартный столбец в DataFrame.df.reset_index(inplace=True) вернет
Выбор определенных столбцов или столбца из DataFrame по их метке
Использование df[[]] в Pandas позволяет выбирать один или несколько столбцов из DataFrame по метке столбца. При использовании двойных квадратных скобок df[[]], внутренний список содержит имена столбцов, которые вы хотите выбрать. Пример использования df[[]] для выбора столбцов по метке: df[['name', 'city']]

df['name'] или df.name, однако в этом случае мы получим объект Series, чтобы получить DataFrame с одним столбцом используем df[['name']].Присвоение конкретного значения всем элементам столбца
df['age'] = 50 присваивает значение 50 каждому элементу столбца ‘age’ в DataFrame df

Создание нового столбца под конкретные значения
df['city_fact'] = df['city'] создает новый столбец ‘city_fact’ в DataFrame df, который содержит те же значения, что и столбец ‘city’.

Удаление столбца
- С помощью оператора
del, который удаляет указанный столбец из DataFrame, изменяя исходный DataFrame, поэтому будьте осторожны, когда используете его для удаления столбцов. Например:del df['city_fact']
- С помощью метода
drop(), который создает и возвращает новый DataFrame без указанного столбца, оставляя исходный DataFrame неизменным, если не указан параметрinplace=True. Используется для безопасного удаления столбцов с возможностью сохранения исходных данных. Может быть использован для удаления нескольких столбцов одновременно. Например:df.drop('city_fact', axis=1), здесь параметрaxis=1указывает, что вы хотите удалить столбец, а не строку.
Выбор строк из DataFrame на основе булевых значений в списке
Использование df[[True, False, True]] в Pandas позволяет фильтровать строки DataFrame на основе булевых значений в списке. В данном случае, булевы значения [True, False, True] указывают, какие строки нужно выбрать: первая и третья строки, т.е. строки с индексами 0 и 2.
В нашем примере d=df[[True, False, True]] вернет

Получение определенных строк и столбцов можно комбинировать, например df[[True, False, False,]][['age']] вернет
![]()
Мультииндекс
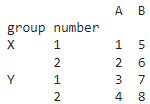
Создание Мультииндекса
pd.MultiIndex.from_arrays() , он полезен, когда у вас уже есть массивы значений для каждого уровня индекса. pd.MultiIndex.from_arrays(arrays, names=None), здесь arrays: Список или массив массивов значений, представляющих значения для каждого уровня индекса.names: (опционально) Список имен для уровней индекса.
import pandas as pd
# Создание массивов значений для каждого уровня индекса
arrays = [['A', 'A', 'B', 'B'], [1, 2, 3, 4]]
# Создание Мультииндекса из массивов значений
multi_index = pd.MultiIndex.from_arrays(arrays, names=['first', 'second'])
print(multi_index)
Создадим DataFrame в который передадим созданный мультииндекс в качестве индекса строк и столбцов
# Создание DataFrame с Мультииндексом в качестве индекса строк и столбцов
data = pd.DataFrame([[1, 2, 3,4], [5, 6, 7,8], [9, 10, 11, 12], [13, 14, 15, 16]], index=multi_index, columns=multi_index)
df = pd.DataFrame(data, index=multi_index, columns=multi_index)
Создание Мультииндекса из произведения значений нескольких массивов.
Для этого используют метод pd.MultiIndex.from_product(iterables, names=None) , где
iterables: Список или кортеж из массивов значений или итерируемых объектов, которые будут использоваться для создания всех возможных комбинаций.names: (опционально) Список имен для уровней индекса.
import pandas as pd
# Создание массивов значений для каждого уровня индекса
array1 = ['A', 'B']
array2 = [1, 2]
# Создание Мультииндекса из произведения значений массивов
multi_index = pd.MultiIndex.from_product([array1, array2], names=['first', 'second'])
data = {
'Value1': [10, 20, 30, 40],
'Value2': [100, 200, 300, 400],
'Value3': [1, 2, 3, 4],
}
# Создание DataFrame с Мультииндексом в качестве индекса строк
df = pd.DataFrame(data, index=multi_index)
print(df)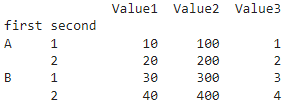
Создание Мультииндекса из списка кортежей
Для этого используют метод pd.MultiIndex.from_tuples(tuples, names=None) , где
tuples: Список кортежей, где каждый кортеж представляет значения для каждого уровня индекса (новая строка мультииндекса).names: (опционально) Список имен для уровней индекса.
import pandas as pd
# Создание списка кортежей с значениями для каждого уровня индекса
tuples = [('A', 1), ('A', 2), ('B', 1), ('B', 2)]
# Создание Мультииндекса из списка кортежей
multi_index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second'])
# Создание DataFrame с Мультииндексом в качестве индекса строк
df = pd.DataFrame({'Value': [10, 20, 30, 40]}, index=multi_index)
print(df)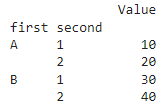
Свойства и методы мультииндекса
Получение мультииндекса из DataFrame
Для этого используют атрибут index датафрейма. Если датафрейм уже имеет Мультииндекс в качестве индекса строк, то атрибут index будет возвращать этот Мультииндекс.
import pandas as pd
tuples = [('A', 1), ('A', 2), ('B', 1), ('B', 2)]
index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second'])
data = {'values': [10, 20, 30, 40]}
df = pd.DataFrame(data, index=index)
print (df)
# Получение Мультииндекса из датафрейма
multi_index = df.index
print(multi_index)
Для получения мультииндекса столбцов используйте df.columns .
Получение числа уровней в Мультииндексе
Для получения количества уровней в Мультииндексе датафрейма в библиотеке Pandas, вы можете использовать атрибут nlevels. Этот атрибут возвращает количество уровней в Мультииндексе.
# Получение числа уровней в Мультииндексе
num_levels = df.index.nlevels
print("Число уровней в Мультииндексе:", num_levels)
# Получение числа уровней в Мультииндексе столбцов
num_levels_columns = df.columns.nlevels
print("Число уровней в Мультииндексе столбцов:", num_levels_columns)Получение кортежа с длиной каждого уровня
для это используем атрибут levshape— df.index.levshape
Получение имен уровней Мультииндекса
В Pandas для этого используется атрибут names — df.index.names
Изменение имен индексов
Это можно выполнить с помощью рассмотренного выше атрибута, например df.index.names = [‘one’, ‘two’]
или с помощью метода set_names() , например df.index.set_names([‘level1’, ‘level2’], inplace=True)
Изменение имени конкретного уровня мультииндекса
set_names(), пример df.index.set_names(«Many», level=1, inplace=True)Получение элементов мультииндекса
levels — df.index.levelsCброс индексов датафрейма и превращения их в столбцы
reset_index() , например df_reset = df.reset_index()Удаление одного или нескольких уровней из Мультииндекса
df.droplevel(level) , где level: Уровень или список уровней, которые нужно удалить из Мультииндекса.droplevel() на объекте MultiIndex в столбцах, Арифметические операции
В библиотеке Pandas доступны различные арифметические операции? вот они: Сложение (+), Вычитание (-), Умножение (*), Деление (/), Вычисление остатка от деления(%), Целочисленное деление (//), Возведение в степень (**)
Прибавление числа и списка
- df+10 приводит к прибавлению числа ко всем элементам, исходная серия или датафрейм не меняются.
- df1+[1,2,3,4,5] Количество элементов списка должно совпадать с количеством столбцов. Нулевой элемент списка складывается с к каждому элементу первого столбца DataFrame и т.д.
Арифметические операции с Nan
возвращают Nan, например df1 = df1+np.nan
В Python и библиотеке NumPy для обозначения отсутствующего или неопределенного значения используется константа np.nan (или np.NaN). Это специальное значение представляет собой «Not a Number» и используется для обозначения отсутствия данных или некорректных операций с числами. Поэтому для использования NaN в Python, особенно
Операции между DF(датафреймами)
Сложение двух датафреймов, например df1+df2 (все остальные операции происходят по тому же принципу).

При складывании двух DF результирующий датафрейм будет иметь индексы строк и столбцов обоих DF. Это выравнивание индексов.
Выравнивание индексов (index alignment) в библиотеке Pandas означает автоматическое выравнивание данных по индексам при выполнении операций между объектами Pandas, такими как DataFrame или Series. Когда вы производите операции (например, сложение, вычитание, умножение) между двумя объектами Pandas, выравнивание индексов гарантирует, что данные будут выровнены по индексам перед выполнением операции. Это позволяет более гибко работать с данными, даже если индексы не совпадают.
Специальные методы для выполнения арифметических операций
В библиотеке Pandas для выполнения арифметических операций доступны специальные методы, которые позволяют более гибко работать с данными. Некоторые из специальных методов для выполнения арифметических операций в Pandas включают:
add(): Метод для сложения (или других арифметических операций) между объектами Pandas, например DataFrame или Series.
result = df1.add(df2, fill_value=0) или result = df.add([10, 20], axis=’columns’)
Синтаксис: DataFrame.add(other, axis='columns', level=None, fill_value=None), где:
other: Другой объект Pandas, которое будет добавлено к вашему DataFrame или Series.axis: Определяет ось, по которой будет производиться операция. По умолчанию ‘columns’.level: Уровень мультииндекса, по которому будет производиться операция.fill_value: Значение, которое будет использоваться для заполнения отсутствующих значений при выполнении операции.
sub(): Метод для вычитания между объектами Pandas. Также поддерживает параметр fill_value.
mul(): Метод для умножения между объектами Pandas. Также поддерживает параметр fill_value.
div(): Метод для деления между объектами Pandas. Также поддерживает параметр fill_value.
pow(): Метод в библиотеке Pandas используется для возведения значений объекта Pandas в указанную степень.
mod(): Метод в Pandas используется для выполнения поэлементного деления с остатком (модуля) между значениями объекта Pandas и указанным числом или объектом Pandas.
Операции сравнения
В Pandas операции сравнения выполняются с использованием стандартных операторов сравнения, таких как >, <, ==, !=, >=, <=. Эти операции возвращают булевы значения (True или False) в зависимости от результата сравнения.
Вот некоторые основные операции сравнения в Pandas:
Булевы операции сравнения:
>: Больше
<: Меньше
==: Равно
!=: Не равно
>=: Больше или равно
<=: Меньше или равно
Всегда при сравнении np.nan == np.nan , как и при сравнении Nan с любым числом np.nan == 100 будет возвращаться False.
Сравнение Series с числом
s = pd.Series([5, 15, 8, 12, 3])
result = s > 10
print(result)В этом примере, s > 10 создает новую Series с булевыми значениями, где True означает, что соответствующее значение в Series больше 10, а False — нет.

Сравнение Series с списком
количество элементов в списке должно совпадать с количеством элементов в серии, идет последовательное сравнение — нулевой элемент списка с нулевой строкой серии и т.д.
s = pd.Series([5, 15, 8, 12, 3])
sl = [5, 15, 8, 12, 3]
s == sl
Сравнение Series с другой Series
data1 = { 'r1': [10, 20, 30, 40],'r2': [10, 6, 30, 8],'r3': [9, 10, 11, 12],'r4': [13, 14, 15, 16],'r5': [17, 18, 1.0, 20]}
df1 = pd.DataFrame(data1)
df1['r1']==df1['r2']
Сравнение DataFrame с числами
data1 = {'r1': [10, 20, 30, 40],'r2': [10, 6, 30, 8],'r3': [9, 10, 11, 12],'r4': [13, 14, 15, 16],'r5': [17, 18, 1.0, 10]}
df1 = pd.DataFrame(data1)
df1==10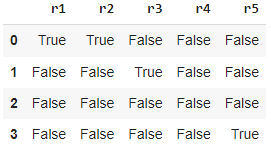
Сравнение DataFrame со списком
Количество элементов списка должно соответствовать количеству столбцов. Нулевой элемент списка сравнивается со всеми значения из первого столбца DataFrame и т.д.
Сравнение двух DataFrame
При сравнении должны совпадать индексы строк и столбцов, а также их последовательность.
Специальные методы для проведения сравнения
Pandas предоставляет специальные методы для проведения сравнения DataFrames. Эти методы позволяют сравнивать DataFrames на основе их значений, формы и типов данных. Методы сравнения работают по одному принципу (одинаково).
Вот список методов:
eq(other): Равно ==ne(other): Не равно !=gt(other): Больше >ge(other): Больше или равно >=lt(other): Меньше <le(other): Меньше или равно <=
При использовании этих методов используется предварительное выравнивание индексов, т.е. можно например сравнить датафреймы, имеющие частично одинаковые и разные индексы.
Метод equals()
Метод equals() проверяет, содержат ли два объекта одни и те же элементы. Эта функция позволяет сравнивать две серии или DataFrames друг с другом, чтобы увидеть, имеют ли они одинаковую форму и элементы. NaN в одном и том же месте считаются равными. Индекс строки/столбца не обязательно должен иметь один и тот же тип, если значения считаются равными. Соответствующие столбцы и индексы должны иметь один и тот же тип dtype.
Например сравним DataFrame самим с собой: df1.equals(df1) — вернется True
если столбцы поменяем местами df1.equals(df1[[‘r2′,’r3’, ‘r1’]]), то вернется False
Метод all()
Метод all() в библиотеке Pandas проверяет, все ли элементы в объекте данных удовлетворяют условию. Если все элементы соответствуют условию, то метод вернет True, иначе вернет False.
import pandas as pd
data = {"A": [1, 2, 3], "B": [4, 5, 6]}
df = pd.DataFrame(data)
result = df["A"].gt(0).all()
print(result) # Вернет True, так как все элементы в столбце 'A' больше 0Метод any()
Метод any() в библиотеке Pandas проверяет, соответствует ли хотя бы один элемент в объекте данных заданному условию. Если хотя бы один элемент соответствует условию, то метод вернет True, иначе вернет False.
import pandas as pd
data = {"A": [1, 2, 3], "B": [4, 5, 6]}
df = pd.DataFrame(data)
result = df["A"].gt(2).any()
print(result) # Вернет True, так как хотя бы один элемент в столбце 'A' больше 2Фильтрация данных по логическому условию
import pandas as pd
data = {
'name': ['Сергей', 'Антон', 'Михаил', 'Светлана'],
'age': [49, 36, 18, 45],
'высшее образование': [True, False, True, False],
}
df = pd.DataFrame(data)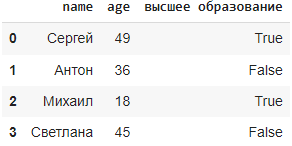
Фильтрация с помощью списка с булевыми значениями
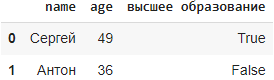
Фильтрация с помощью Series или столбца с bool значениями

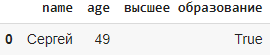
Фильтрация по логическому значению


and заменяется на &
or заменяется на |
not заменяется на ~
& ,~ , | , == , <, > ,<= .
Метод isin()
Метод isin() в библиотеке Pandas используется для фильтрации данных на основе совпадения значений с заданным списком или другим объектом данных. Он возвращает булеву серию, указывающую, содержится ли значение в исходном объекте данных в списке, переданном в метод isin().


Метод query()
query() в библиотеке Pandas используется для фильтрации данных с помощью логических выражений. Он позволяет выполнять фильтрацию строк на основе условий, указанных в виде строки с использованием специального синтаксиса. Логические операторы (not, and,or) и операторы сравнения (==, <, > != итд) используются стандартно. Также можно ссылаться на имена столбцов, которые не являются допустимыми именами переменных Руthon, заключив их в обратные метки ` (ё в анг. раскладке).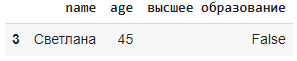
Работа с пропусками в данных
Рассмотрим следующие методы на этом примере:
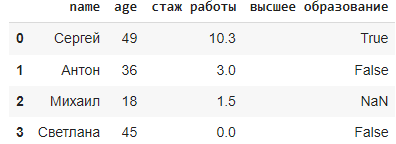
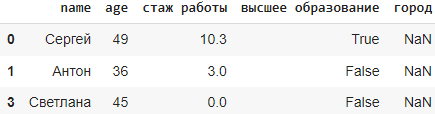
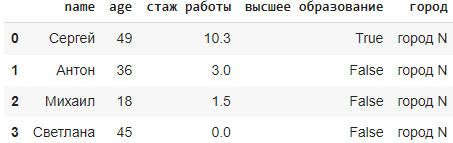
data = {
'name': ['Сергей', 'Антон', 'Михаил', 'Светлана'],
'age': [49, 36, 18, 45],
'стаж работы': [10.3, 3.0, 1.5, 0],
'высшее образование': [True, False, np.nan, False],
'город': [np.nan, np.nan, np.nan, np.nan]
}
df = pd.DataFrame(data)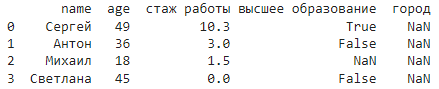
Метод dropna()
Метод dropna() в библиотеке Pandas используется для удаления строк или столбцов, содержащих пропущенные значения (NaN). По умолчанию, он удаляет строки с хотя бы одним пропущенным значением. Исходный датафрейм не меняется, чтобы он изменился используют параметр inplace(см.синтаксис).
Синтаксис: DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False), где:
axis: определяет, удалять строки (наблюдения) с пропущенными значениями (axis=0) или столбцы (при axis=1).
how: определяет, какие строки или столбцы удалять — ‘any’ (по умолчанию) удаляет строку или столбец, если есть хотя бы одно пропущенное значение, ‘all’ удаляет строку или столбец, если все значения пропущены.
thresh: минимальное количество непропущенных значений, необходимое для сохранения строки или столбца.
subset: список столбцов или индексов, которые нужно рассматривать при удалении пропущенных значений.
inplace: логический параметр, указывающий, изменять ли исходный DataFrame или возвращать новый.
Например:
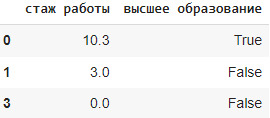
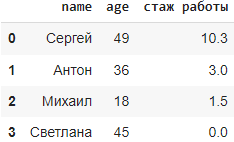
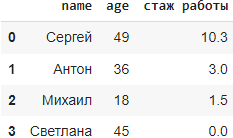
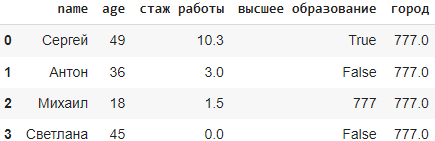
Метод fillna()
fillna() в библиотеке Pandas используется для замены пропущенных (NaN) значений в датафрейме определенным значением или стратегией заполнения. Метод полезен для обработки пропущенных значений при подготовке данных к анализу или визуализации, когда желательно не отбрасывать полезные данные, а заполнять отсутствующие данные. Исходный датафрейм не меняется, чтобы он изменился используют параметр inplace(см.синтаксис).Синтаксис: DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None), где:
value: значение или словарь значений для замены пропущенных значений.
method: метод заполнения пропущенных значений. Например, ‘ffill’ заполняет пропущенные значения предыдущими не-NA значениями.
axis: ось, по которой будет производиться заполнение (0 для строк, 1 для столбцов).
inplace: логический параметр, указывающий, изменять ли исходный DataFrame или возвращать новый.
limit: максимальное количество пропущенных значений для замены на указанное значение.
Используем приведенный выше пример датафрейма.
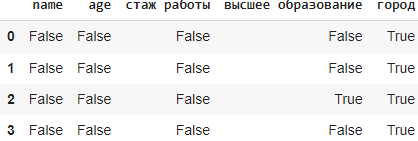
Метод isna()
Метод isna() в библиотеке Pandas используется для определения пропущенных значений (NaN) в датафрейме. Он возвращает новый датафрейм той же формы, что и исходный, заполненный булевыми значениями, где True указывает на пропущенное значение, а False — на не-пропущенное значение.

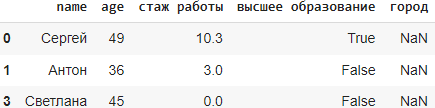
чтобы получить строки, которые не имеют в столбцах пропуски выполним
Метод notna()
notna() в библиотеке Pandas используется для определения не-пропущенных значений (не NaN) в датафрейме. Он возвращает новый датафрейм той же формы, что и исходный, заполненный булевыми значениями, где True указывает на не-пропущенное значение, а False — на пропущенное значение. Этот метод полезен для проверки наличия не-пропущенных значений в данных и может использоваться для фильтрации или обработки данных в зависимости от их наличия.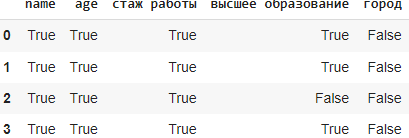
УДАЛЕНИЕ СТРОК И СТОЛБЦОВ. Метод astype(), drop(), drop_duplicates()
Рассмотрим следующие методы на этом примере:
import pandas as pd
import numpy as np
data = {
'B': [10, 20, 30, 40],
'A': [5, 6, 7, np.nan],
'C': [5, 15, 36, 52],
}
df = pd.DataFrame(data)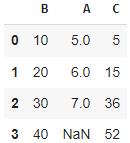
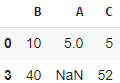
Метод drop()
Метод drop() в библиотеке Pandas используется для удаления указанных меток, как по строкам, так и по столбцам.
Синтаксис: DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise') , где параметры:
labels: метки (индексы или названия) для удаления.
axis: определяет ось, по которой будут удаляться метки (0 для строк, 1 для столбцов).
index: альтернативный способ указания меток строк для удаления.
columns: альтернативный способ указания меток столбцов для удаления.
level: используется для мультииндекса, указывает уровень, на котором происходит удаление.
inplace: если True, то изменения будут внесены в исходный объект DataFrame.
errors: определяет, как обрабатывать ошибки при удалении.
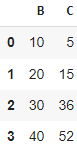
Можно совмещать удаление строк и столбцов, например df.drop(index=[0], columns=[‘A’])
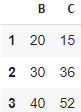
Метод astype()
astype() в библиотеке Pandas используется для приведения типов данных в объекте DataFrame или Series к указанному типу данных. DataFrame.astype(dtype, copy=True, errors='raise'), где:dtype: тип данных, к которому нужно привести объект (например, ‘int’, ‘float’, ‘str’, ‘datetime’ и т. д.).
copy: если True, то создается копия объекта с измененными типами данных.
errors: определяет, как обрабатывать ошибки при преобразовании типов.
Метод drop_duplicates()
Метод drop_duplicates() в библиотеке Pandas используется для удаления дубликатов строк из DataFrame.
Синтаксис DataFrame.drop_duplicates(subset=None, keep='first', inplace=False), где:
subset: Опциональный параметр, который позволяет указать столбцы или столбец, по которым нужно проверять наличие дубликатов.
keep: Определяет, какую из дублирующихся строк оставить. Возможные значения:
'first': Оставить первое вхождение каждой строки (по умолчанию).
'last': Оставить последнее вхождение каждой строки.
False: Удалить все дублирующиеся строки.
inplace: Булевый параметр, определяющий, следует ли применять изменения к исходному DataFrame (если True) или создать копию с изменениями (если False).
Метод drop_duplicates() анализирует строки в DataFrame и эффективно удаляет те строки, которые полностью совпадают с другими строками (дубликаты), оставляя только уникальные строки.
Пример:
data = {'A': [1, 2, 2, 3, 4],
'B': ['a', 'b', 'b', 'c', 'd']}
df = pd.DataFrame(data)
df.drop_duplicates(inplace=True)
print(df)
Знакомство с данными. Методы head(), info(), describe().
Метод df.info()
Метод info() в библиотеке Pandas используется для получения информации о DataFrame, включая общее количество записей, типы данных в каждом столбце, использование памяти и наличие пропущенных значений. Эта информацию может быть полезна при первоначальном анализе данных, включая типы данных, наличие пропущенных значений и использование памяти.
Синтаксис DataFrame.info(verbose=None, buf=None, max_cols=None, memory_usage=None, null_counts=None), где:
verbose: если True, то печатается вся информация о DataFrame; если False, то печатается краткая информация.
buf: поток для вывода информации (по умолчанию — stdout).
max_cols: максимальное количество столбцов для отображения.
memory_usage: если True, то показывает использование памяти по столбцам в DataFrame.
null_counts: если True, то показывает количество нулевых значений.
Метод head()
Метод head() в библиотеке Pandas используется для отображения первых нескольких строк DataFrame или Series.
DataFrame.head(n=5) , можно указать иное количество строк, по умолчанию 5
Метод tail()
Метод tail() в библиотеке Pandas используется для отображения последних нескольких строк DataFrame или Series.
DataFrame.tail(n=5), можно указать иное количество строк, по умолчанию 5
Метод describe()
Метод describe() в библиотеке Pandas используется для получения статистического описания числовых данных в DataFrame или Series.
Синтаксис: DataFrame.describe(percentiles=None, include=None, exclude=None), где:
percentiles: список процентилей, которые следует включить в результат (по умолчанию включены 25%, 50% и 75%).
include: типы данных для включения при описании (по умолчанию включаются только числовые типы данных).
exclude: типы данных для исключения при описании.
При использовании команды print(df.describe()) получим результат, каждая строка в котором будет представлять собой различные статистические показатели для числовых столбцов в DataFrame df. Вот какие статистические показатели представлены в каждой строке:
count: количество непустых значений в столбце.
mean: среднее значение.
std: стандартное отклонение.
min: минимальное значение.
25%, 50%, 75%: первый, второй (медиана) и третий квартили соответственно.
max: максимальное значение.
Эти статистические показатели помогают понять распределение данных в каждом числовом столбце и выявить основные характеристики данных, такие как центральную тенденцию, разброс и форму распределения. Пример смотрите чуть ниже.
Другие распространенные атрибуты DataFrame
shape: возвращает размер DataFrame в виде кортежа (число строк, число столбцов).index: возвращает индекс DataFrame.columns: возвращает имена столбцов DataFrame.dtypes: возвращает типы данных столбцов DataFrame.empty: возвращает True, если DataFrame пустой, иначе False.size: возвращает количество элементов в DataFrame.T: возвращает транспонированный DataFrame. Транспонированный DataFrame — это DataFrame, в котором столбцы становятся строками, а строки — столбцами.isna(): возвращает DataFrame с булевыми значениями, которые указывают, имеют ли значения в DataFrame значение NaN.
Создадим датафрейм
data = {
"Open": [100.0, 110.0, 105.0],
"High": [105.0, 115.0, 110.0],
"Low": [95.0, 100.0, 102.0],
"Close": [102.0, 112.0, 108.0],
"Volume": [1000, 1500, 1200],
}
ohlcv_data = pd.DataFrame(data)print(ohlcv_data.shape) # выводит: (3, 5)
print(ohlcv_data.index) # выводит: RangeIndex(start=0, stop=3, step=1)
print(ohlcv_data.columns) # выводит: Index(['Open', 'High', 'Low', 'Close', 'Volume'], dtype='object')
print(ohlcv_data.dtypes) # выводит:
# Open float64
# High float64
# Low float64
# Close float64
# Volume int64
# dtype: object
print(ohlcv_data.empty) # выводит: False
print(ohlcv_data.size) # выводит: 15
print(ohlcv_data.describe()) # выводит:
# Open High Low Close
# count 3.000000 3.000000 3.000000 3.000000
# mean 105.000000 109.66667 101.66667 106.66667
# std 10.500000 10.500000 5.000000 5.000000
# min 95.000000 100.00000 95.000000 102.000000
# 25% 99.666667 109.00000 99.000000 106.000000Доступ к ячейкам и к группе строк и столбцов. Методы — получатели at, iat, loс и iloc
Рассмотрим следующие методы на этом примере:
import pandas as pd
import numpy as np
data = {
"name": ["Сергей", "Антон", "Петр","Анна"],
"age": [25, 35, 45,20],
"children": [True, False, True,False],
}
df = pd.DataFrame(data, index=["user1", "user2", "user3","user4"])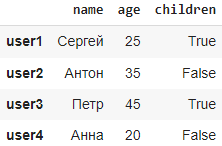
Метод iat[]
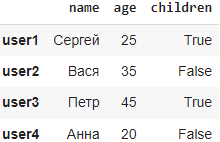
Метод iat[] в библиотеке Pandas используется для доступа и изменения значения конкретной ячейки в DataFrame по индексe строки и столбца. Метод удобен, но требует знания числовых индексов строк и столбцов. Метод iat[] в Pandas ожидает числовые индексы для строки и столбца, а не метки (названия) строк и столбцов.
Синтаксис: DataFrame.iat[row_index, column_index], где:
row_index: числовой индекс строки, к которой вы хотите обратиться.
column_index: числовой индекс столбца, к которому вы хотите обратиться.
Например df.iat[1,0]=»Вася»
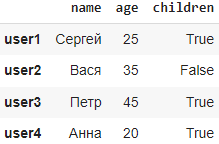
Метод at[]
Метод at[] в библиотеке Pandas используется для доступа и изменения значения конкретной ячейки в DataFrame по меткам (названиям) строки и столбца.
Синтаксис DataFrame.at[row_label, column_label], где:
row_label: метка (название) строки, к которой вы хотите обратиться.
column_label: метка (название) столбца, к которому вы хотите обратиться.
Например print(df[‘name’].at[‘user4’]) выведет #Анна, а df.at[«user4″,»children»]=True изменит значение ячейки.
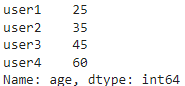
Метод iloc[]
Метод iloc[] в библиотеке Pandas извлекает строки и столбцы по позиции индекса. Этот метод позволяет обращаться к данным по числовым индексам, а не по меткам (названиям) строк и столбцов.
Синтаксис iloc[]DataFrame.iloc[row_index, column_index], где:
row_index: числовой индекс строки (начиная с 0), к которой вы хотите обратиться.
column_index: числовой индекс столбца (начиная с 0), к которому вы хотите обратиться.
С помощью метода мы можем получить группы строк и столбцов, справедливы следующие варианты:
df.iloc[индекс строки, индекс столбца]: Выбор конкретной ячейки по числовому индексу строки и столбца.
df.iloc[[список индексов строк], [список индексов столбцов]]: Выбор определенных строк и столбцов по их числовым индексам в виде списков.
df.iloc[срезы индексов, срезы индексов]: Выбор диапазона строк и столбцов с помощью срезов числовых индексов.
Например:
Метод loc[]
loc[] в библиотеке Pandas используется для доступа и изменения значений в DataFrame по меткам (названиям) строк и столбцов. Этот метод позволяет обращаться к данным по меткам, а не по числовым индексам.DataFrame.loc[row_label, column_label], где:row_label: метка (название) строки, к которой вы хотите обратиться.
column_label: метка (название) столбца, к которому вы хотите обратиться.
Например df.loc[:,’age’]
loc[] в Pandas, вы можете использовать логическую индексацию. Логическая индексация позволяет передавать условия фильтрации в loc[], чтобы извлечь только те строки, которые соответствуют условиям. Например:# Создание условия фильтрации (булевого массива)
condition = df['age'] < 89
# Использование логической индексации в методе loc[]
result = df.loc[condition]Полезные методы unique(), nunique(), value_counts(), sort_values(), map(), isin(), replace(), size(), empty(), nlargest и nsmallest.
Используем для примера следующий датафрейм:
import pandas as pd
import numpy as np
data = {
"name": ["Сергей", "Антон", "Петр","Анна"],
"age": [25, 35, 45,20],
"auto": [True, False, True,False],
}
df = pd.DataFrame(data, index=["user1", "user2", "user3","user4"])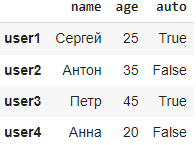
Метод unique()
Метод unique() в библиотеке Pandas используется для получения уникальных значений из столбца или серии данных. Этот метод возвращает массив, содержащий все уникальные значения в порядке их появления в исходном столбце.
Синтаксис unique_values = df['столбец'].unique(), где:
df['столбец'] обращается к столбцу «столбец» в DataFrame df.
Метод unique() не имеет дополнительных параметров и возвращает массив, содержащий все уникальные значения из указанного столбца.
Метод nunique()
Метод nunique() в библиотеке Pandas используется для подсчета количества уникальных значений в серии или столбце данных. Он возвращает количество уникальных значений в указанной серии.
Синтаксис Series.nunique(dropna=True), где:
dropna: Если установлено значение True (по умолчанию), пропущенные значения будут игнорироваться при подсчете уникальных значений.
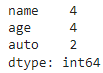
Метод value_counts()
Метод value_counts() в библиотеке Pandas используется для подсчета уникальных значений в серии данных и возвращает серию, в которой индексами являются уникальные значения, а значениями — количество их появлений в исходной серии.
Синтаксис Series.value_counts(normalize=False, sort=True, ascending=False, bins=None, dropna=True), где:
normalize: Если установлено значение True, возвращает относительные частоты вместо абсолютных значений.
sort: Управляет сортировкой результатов (по умолчанию True — сортировка значений).
ascending: Управляет порядком сортировки (по умолчанию False — сортировка по убыванию).
bins: Определяет количество корзин для группировки значений (используется при анализе числовых данных).
dropna: Если установлено значение False, пропущенные значения будут включены в подсчет.
Например df[‘auto’].value_counts() вернет

Метод sort_values()
Метод sort_values() в библиотеке Pandas используется для сортировки значений в серии данных или в столбце DataFrame. Он позволяет отсортировать значения в порядке возрастания или убывания.
Синтаксис DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', ignore_index=False), где:
by: Столбец или список столбцов, по которым будет производиться сортировка.
axis: Определяет по какой оси производить сортировку (0 — по строкам, 1 — по столбцам).
ascending: Управляет порядком сортировки (True — по возрастанию, False — по убыванию).
inplace: Указывает, следует ли применить изменения к исходному DataFrame.
kind: Метод сортировки (по умолчанию ‘quicksort’).
na_position: Определяет позицию пропущенных значений при сортировке (‘first’ — в начале, ‘last’ — в конце).
ignore_index: Если установлено значение True, индексы будут проигнорированы и заменены на новую последовательность.
Например df.sort_values(by=’age’, ascending=False) вернет
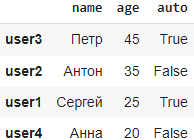
Метод map()
Метод map() в библиотеке Pandas используется для замены значений в серии данных другим значением, которое может быть получено из функции, словаря или Series. Метод возвращает новый объект не меняя старый.
Вот общий синтаксис метода map():
Синтаксис Series.map(arg, na_action=None), где:
arg: Может быть словарем, серией или функцией, которая определяет отображение значений.
na_action: Определяет действие при встрече пропущенных значений (None — оставить пропущенные значения, ‘ignore’ — пропустить пропущенные значения).
Замена значений в серии с помощью словаря:
mapping = {'A': 1, 'B': 2, 'C': 3}
df['column'].map(mapping)Применение функции к значениям в серии:
def custom_function(x):
return x * 2
df['column'].map(custom_function)Замена значений в серии с использованием другой серии:
other_series = pd.Series([10, 20, 30])
df['column'].map(other_series)Метод map() позволяет гибко изменять значения в серии данных на основе заданных правил или функций.
Метод isin(values)
Метод isin(values) в библиотеке Pandas используется для фильтрации данных по значениям в серии, в столбце DataFrame или Index-е. Он возвращает булеву серию, указывающую, содержатся ли значения из серии данных в переданном списке значений. Метод возвращает новый объект не меняя старый. Метод isin() удобен для фильтрации данных на основе конкретных значений.
Синтаксис Series.isin(values):, где:
values: Список значений или итерируемый объект, по которому будет производиться фильтрация.
filter_values = ['value1', 'value2', 'value3']
filtered_data = df['column'].isin(filter_values)В этом примере isin() вернет булеву серию, где каждое значение будет указывать, содержится ли соответствующее значение в столбце «column» DataFrame df в списке filter_values.
Метод replace()
Метод replace() в Pandas используется для замены значений в DataFrame или Series на другие значения.
Вот синтаксис метода df.replace(to_replace, value, inplace=False, limit=None), где:
to_replace — значение или список значений, которые нужно заменить.
value — новое значение, на которое будут заменены указанные значения.
inplace — необязательный параметр, указывающий, нужно ли заменять значения вplace (то есть не создавать новый объект, а изменять существующий). По умолчанию равен False.
limit — необязательный параметр, указывающий максимальное количество замен, которое должно быть выполнено.
Например:
df = pd.DataFrame({ 'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'], 'Age': [25, 30, None, 40, 45], 'Salary': [5000, 6000, 7000, None, 9000] })
# Заменяем значение None на 0
df = df.replace({None: 0})Создаем df с некоторыми значениями None. Затем мы используем метод replace() для замены значения None на 0.
Метод size()
size() — это метод возвращает количество элементов в объекте pandas (Series, DataFrame или Panel). Он является ярлыком для функции len() и может использоваться с любым объектом pandas.
Синтаксис метода df.size() , где df — это объект pandas (DataFrame, Series или Panel
Например: подсчет количества элементов в DataFrame и Series.
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
print(df.size) #6
s = pd.Series([1, 2, 3, 4, 5])
print(s.size) #5Методы nlargest и nsmallest
Методы nlargest и nsmallest в библиотеке Pandas используются для поиска наибольших и наименьших значений в объекте DataFrame. Методы nlargest и nsmallest можно вызывать только для числовых столбцов и столбцов с датами.
nlargest(n, columns): возвращает n наибольших значений из указанных столбцов.
nsmallest(n, columns): возвращает n наименьших значений из указанных столбцов.
data = {
'Open': [100.0, 110.0, 105.0],
'High': [105.0, 115.0, 110.0],
'Low': [95.0, 100.0, 102.0],
'Close': [102.0, 112.0, 108.0],
'Volume': [1000, 1500, 1200]
}
ohlcv_data = pd.DataFrame(data)
# Наибольшие значения в столбце 'High'
largest_high = ohlcv_data['High'].nlargest(2)
print("Наибольшие значения в столбце 'High':")
print(largest_high)
# Наименьшие значения в столбце 'Low'
smallest_low = ohlcv_data['Low'].nsmallest(1)
print("\nНаименьшее значение в столбце 'Low':")
print(smallest_low)
Функция empty
Функция empty в библиотеке pandas возвращает True, если DataFrame пустой, и False в противном случае.
# Создаем пустой DataFrame
df = pd.DataFrame()
# Проверяем, является ли DataFrame пустым
is_empty = df.empty
print(is_empty) # Вывод: Trueвидеоурок
Метод apply()
Используем для примера следующий датафрейм:
data = {
'A': [1, 2, 3, 4, 5],
'B': [6, 7, 8, 9, 10],
'C': [11, 12, 13, 14, 15],
'D': [16, 17, 18, 19, 20],
'E': [21, 22, 23, 24, 25]
}
df = pd.DataFrame(data)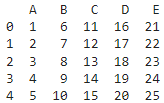
Метод apply() в библиотеке Pandas используется для применения функции к каждому элементу в серии или столбце DataFrame. Этот метод позволяет применять пользовательские функции, лямбда-функции или встроенные функции к данным в DataFrame.
Синтаксис DataFrame.apply(func, axis=0, raw=False, result_type=None, args=(), **kwds), где:
func: Функция, которая будет применена к каждому элементу, строке или столбцу в DataFrame.
axis: Ось, по которой будет применена функция, по умолчанию 0 (0 — по столбцам, 1 — по строкам).
raw: Булево значение, указывающее, передавать ли данные в функцию в виде массивов NumPy (True) или серий Pandas (False).
result_type: Тип данных, который ожидается возвращаемым значением функции (None — позволяет Pandas определять тип автоматически, ‘expand’ — для возврата DataFrame).
args: Дополнительные позиционные аргументы для передачи в функцию.
**kwds: Дополнительные ключевые слова для передачи в функцию.
Практика применения метода

def funcpandas(x):
return x*100 if x.name == 'D' else x-1
df.apply(np.min)
df.apply(funcpandas, axis=0)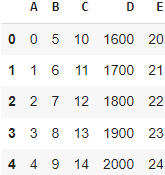
аналогичный результат будет если в метод передать следующую лямбда функцию:
3) df.apply(np.mean, axis=1) вернет серию, содержащие средние значения в каждой строке датафрейма
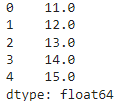
Аналогичный результат даст вариант df.apply(np.mean, axis=1, raw=True), при котором вместо серии мы передаем массив Numpy. При большом количестве данных скорость обработки переданного массива Numpy благодаря raw=True может кратно вырасти.
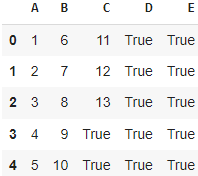
4) передадим в метод apply лямбда функцию
df.apply(lambda x: x.apply(lambda y: True if y > 13 else y))
В этом коде мы используем метод apply() для применения lambda функции к каждому столбцу в DataFrame df. Внутри lambda функции мы используем метод apply() для проверки условия y > 8 по каждому элементу в столбце и замены значений, которые удовлетворяют условию, на True, а остальные значения остаются без изменений.
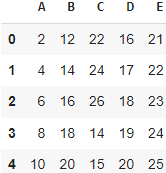
5) передача дополнительных аргументов в функцию с помощью кортежа args
def funcpan(x, a, b):
return x * b if x < a else x
df.apply(lambda x: x.apply(funcpan, args=(14, 2)))В этом коде используется метод apply для применения функции funcpan к каждому столбцу в DataFrame df. Внутри lambda функции мы используем метод apply для применения функции funcpan к каждому элементу в столбце x. Аргументы (14, 2) передаются в функцию funcpan как args. Таким образом, функция funcpan применяется к каждому элементу в каждом столбце df и возвращает новую серию с измененными значениями.
Функции funcpan, которая принимает три аргумента: x (значение), a (пороговое значение) и b (множитель). Функция проверяет, меньше ли x порогового значения a, и если это так, умножает его на b. В противном случае, она возвращает x без изменений.
Агрегация данных. Статистические функции и функций агрегации. Метод agg(). Метод resample().
Агрегация данных в pandas — это процесс, при котором выполняются операции, которые позволяют объединять и комбинировать данные в более высшем уровне. Это может включать такие операции, как суммирование, средние значения, количества и другие статистические вычисления.
В pandas агрегация данных обычно выполняется с помощью метода agg(), который позволяет применять различные функции агрегации к столбцам DataFrame.
Статистические функции и функций агрегации
В Pandas, статистические функции и функции агрегации обычно используются взаимозаменяемо, поскольку функции агрегации часто включают в себя вычисление статистических показателей.
Однако есть тонкая разница между ними:
Статистические функции обычно относятся к функциям, которые вычисляют статистические показатели для конкретного набора данных или столбца, например, среднее значение, медиану, стандартное отклонение и т.д.
Функции агрегации используются для агрегации данных путем применения определенных операций (таких как суммирование, подсчет, нахождение минимума или максимума) к набору данных для создания сводной информации.
Некоторые из наиболее распространенных статистических функций и функций агрегации в Pandas:
sum(): суммирует значения в столбце.mean(): вычисляет среднее значение в столбце.min(): возвращает минимальное значение в столбце.max(): возвращает максимальное значение в столбце.count(): подсчитывает количество непустых значений в столбце.nunique(): подсчитывает количество уникальных значений в столбце.median(): Вычисляет медиану.std(): вычисляет стандартное отклонение в столбце.var(): вычисляет дисперсию в столбце.first(): возвращает первое значение в столбце.last(): возвращает последнее значение в столбце.mode(): возвращает наиболее часто встречающееся значение в столбце.
вот несколько примеров использования статистических функций в Pandas:
Среднее значение (Mean): mean_value = df[‘column’].mean()
Медиана (Median): median_value = df[‘column’].median()
Сумма (Sum): sum_value = df[‘column’].sum()
Минимум (Minimum): min_value = df[‘column’].min()
Максимум (Maximum): max_value = df[‘column’].max()
Стандартное отклонение (Standard Deviation): std_value = df[‘column’].std()
Дисперсия (Variance): var_value = df[‘column’].var()
Выше были перечислены только некоторые из доступных функций агрегации в pandas. Вы также можете использовать их в методе agg() для выполнения различных операций агрегации над вашими данными.
Метод agg()
Метод agg() в библиотеке pandas используется для выполнения агрегационных операций над DataFrame или определенным столбцом. Он позволяет применять несколько функций агрегации к одному или нескольким столбцам, позволяет выполнять различные математические и статистические операции над данными и возвращает результат в виде нового DataFrame.Метод agg() позволяет применять как встроенные функции агрегации, так и пользовательские функции агрегации к столбцам DataFrame.
Синтаксис dataframe.agg({column_name: function}) или dataframe.agg(function, axis), где:
function: Этот параметр определяет функцию(и) агрегации, которые должны быть применены. Это может быть отдельная функция или словарь, сопоставляющий имена столбцов с функциями.
column_name: Этот параметр определяет имя(ей) столбца(ов), на которых должны быть применены функции агрегации. Это может быть отдельное имя столбца или список имен столбцов.
axis— это параметр, который может принимать значения 0 или 1 и используется для указания оси операций, таких как суммирование, группировка, и т.д. Можно использоватьaxis=0для операций по строкам иaxis=1для операций по столбцам.
В Pandas можно использовать как метод
aggс строковыми аргументами, напримерmax,minи т.д., так и функции NumPy, напримерnp.max,np.minи т.д. напрямую. Выбор зависит от конкретного случая использования и личных предпочтений. Использованиеaggсо строками может быть медленнее, чем использование функций NumPy напрямую.При работе с числами обычно используют функции библиотеки Numpy. Но Вы можете использовать и методы, предоставляемые библиотекой Pandas или соответствующими классами, такими как
pd.Seriesиpd.DataFrame.Например, если вы хотите использовать функцию
min()из Numpy в методеagg(), вы можете передать ссылку на функциюnp.minв качестве аргумента. Однакоdf.agg(pd.min)дастошибку, потому что в библиотеке Pandas нет такой функции. Однако, у классовpd.Seriesиpd.DataFrameесть такая функция и вы можете использоватьdf.agg(pd.Series.min), чтобы достичь того же результата, что иdf.agg(np.min).Аналогично, если в DataFrame просят подсчитать среднее и количество элементов во всех столбцах, вы можете использовать
df.agg([np.mean, np.count]). Но поскольку в Numpy нет функцииcount(), то вы получите ошибку. Однако, у классаpd.Seriesесть такая функция и вы можете использоватьdf.agg([np.mean, pd.Series.count]), чтобы достичь желаемого результата.
Используем для примеров наш датафрейм df
df.

def funcpan(seria):
return seria.max()/100
df.agg(funcpan, axis=0)funcpan применяется к каждому столбцу DataFrame df. Максимальное значение каждого столбца вычисляется, а затем делится на 100. Результат представлен в виде Series, содержащего вычисленные значения для каждого столбца.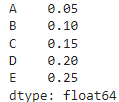
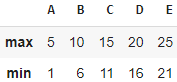
df.agg([max, min], axis=0) [max, min] указывает, что метод agg() должен применить функции max и min , аргумент axis=0 указывает, что функции max и min будут применены к каждому столбцу DataFrame.
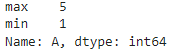
тоже самое применим к серии df[‘A’].agg([max, min])
agg() применяет функцию max к столбцу ‘A’ и функцию min к столбцу ‘B’. Результат представлен в виде Series, содержащего вычисленные значения для каждого указанного столбца.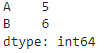
Метод resample()
DataFrame.resample(rule, axis=0, closed=None, label=None, convention='start', kind=None, loffset=None, base=0, on=None, level=None), где:rule: Строка, определяющая правило для ресемплинга.'T' или 'min': ресемплирование по минутам
'H': ресемплирование по часам
'D': ресемплирование по дням
'W': ресемплирование по неделям
'M': ресемплирование по месяцам
'Q': ресемплирование по кварталам
'Y': ресемплирование по годам
axis: Определяет ось, по которой будет производиться ресемплинг (по умолчанию 0 — по строкам).closed: Указывает, какой конец интервала включать в результирующий интервал (‘right’, ‘left’, None).label: Указывает, как маркировать результирующий интервал (‘right’, ‘left’, None).convention: Определяет, какой конец интервала считать началом (‘start’, ‘end’).kind: Определяет тип ресемплинга (‘timestamp’, ‘period’).
loffset: Смещение для дополнительной настройки меток результирующего индекса.
base: Определяет базовую дату для отсчета от временного индекса.
on: Имя столбца, по которому производится ресемплинг.
level: Уровень мультииндекса, по которому производится ресемплинг.
# Пример ресемплинга дневных данных в месячные данные
df.resample('M').mean()Этот пример ресемплирует временные данные из ежедневных в ежемесячные, вычисляя среднее значение для каждого месяца.
Метод resample является мощным инструментом для изменения частоты временных данных и агрегирования их с различными правилами. Подробная документация по методу resample доступна на официальном сайте Pandas.
Группировка данных. Метод groupby()
Группировка данных в Pandas — это операция, при которой данные в DataFrame группируются по значениям определенных столбцов и применяются функции агрегации к данным в каждой группе. Это полезно, когда вы хотите выполнить статистические вычисления или операции над данными, сгруппированными по определенным критериям.
В Pandas для группировки данных используется метод groupby(). Он принимает один или несколько столбцов, по которым нужно сгруппировать данные, и возвращает объект GroupBy, который представляет сгруппированные данные.
Метод groupby() в Pandas используется для группировки данных в DataFrame по значениям определенных столбцов. Он возвращает объект GroupBy, который представляет сгруппированные данные.
Синтаксис df.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, observed=False), где:
by — это столбец или список столбцов, по которым нужно сгруппировать данные. Если не указано, то используются все столбцы DataFrame.
axis — это ось, по которой нужно выполнить группировку. По умолчанию, равно 0, что означает группировку по строкам. Если указано 1, то группировка выполняется по столбцам.
level — это уровень индекса, по которому нужно выполнить группировку. Полезно, когда используется многоуровневый индекс.
as_index — это флаг, указывающий, должен ли новый индекс содержать значения, по которым выполняется группировка. По умолчанию, равен True.
sort — это флаг, указывающий, нужно ли сортировать данные по группируемым значениям. По умолчанию, равен True.
dropna — при группировке данных строки с пропусками (NaN) будут удалены, если dropna=True . По умолчанию, равен False.
Для примеров используем следующий датафрейм
import pandas as pd
# Создаем примерный DataFrame
df = pd.DataFrame({
'Имя': ['Alice', 'Petr', 'Anna', 'Timur', 'Lev'],
'Возраст': [25, 30, 35, 40, 45],
'Зарплата': [5000, 6000, 7000, 8000, 9000]
})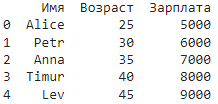
Группировка данных по нескольким столбцам
# Группируем данные по 2 столбцам
grouped = df.groupby(['Имя', 'Возраст'])
# Применяем функцию агрегации к данным в каждой группе
grouped.agg({'Возраст': 'mean', 'Зарплата': 'sum'})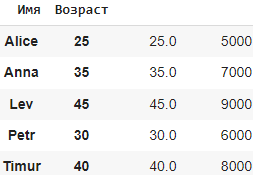
Группировка данных с использованием условных выражений
# Группируем данные по значениям столбца 'Возраст', которые больше 30
grouped = df.groupby(df['Возраст'] > 30)
# Применяем функцию агрегации к данным в каждой группе
grouped.agg({'Имя': 'count', 'Зарплата': 'sum'})
# Определяем пользовательскую функцию для группировки данных
def custom_function(group):
# Выполняем какую-то операцию над каждой группой данных
average_salary = group['Зарплата'].mean()
return pd.Series({'Average Salary': average_salary})
# Группируем данные по столбцу 'Возраст' и применяем пользовательскую функцию к каждой группе
grouped = df.groupby('Возраст')
grouped.apply(custom_function)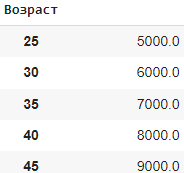
Метод groupby() в pandas является генератором. Это означает, что он последовательно будет возвращать новую группу при каждом обращении к нему. При использовании метода apply() совместно с groupby(), в функцию, которая передается в apply(), будет целиком передаваться тот объект, который возвращает groupby().
Объединение данных. Метод concat(), merge()
Самый простой способ объединить два набора данных — конкатенация.
В контексте pandas, конкатенация заключается в объединении нескольких DataFrame или Series объектов в один большой объект.
Метод concat()
Метод concat позволяет объединить несколько объектов DataFrame или Series по определенной оси (обычно это ось строк).
Синтаксис pd.concat([objs], axis=0, join='outer', ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, copy=True), где:
objs — список объектов DataFrame или Series, которые нужно объединить.
axis — ось, по которой будут объединены объекты. По умолчанию равен 0, что означает объединение по оси строк.
join — определяет, как будут объединены объекты. Возможные значения: ‘inner’ (внутнее объединение), ‘outer’ (внешнее объединение), ‘left’ (левое внешнее объединение) и ‘right’ (правое внешнее объединение).
ignore_index — если True, то индекс объединенных объектов будет проигнорирован.
Для примеров используем 3 датафрейма
df1 = pd.DataFrame({
'col1': ['c1-1', 'c1-2', 'c1-3', 'c1-4'],
'col2': ['c2-1', 'c2-2', 'c2-3', 'c2-4'],
'col3': ['c3-1', 'c3-2', 'c3-3', 'c3-4'],
'col4': ['c4-1', 'c4-2', 'c4-3', 'c4-4']
}, index=[0, 1, 2, 3])
df2=pd.DataFrame({
'col1':['c1-5', 'c1-6', 'c1-7', 'c1-8'],
'col2':['c2-5', 'c2-6', 'c2-7', 'c2-8'],
'col3':['c3-5', 'c3-6', 'c3-7', 'c3-8'],
'col4':['c4-5', 'c4-6', 'c4-7', 'c4-8']
}, index=[2, 3, 4,5])
df3 = pd.DataFrame({
'col1': ['c1-9', 'c1-10', 'c1-11', 'c1-12'],
'col2': ['c2-9', 'c2-10', 'c2-11', 'c2-12'],
'col3': ['c3-9', 'c3-10', 'c3-11', 'c3-12'],
'col4': ['c4-9', 'c4-10', 'c4-11', 'c4-12']
}, index=[4, 5, 6, 7])
При вызове метода concat, мы передаем список объектов DataFrame, которые нужно объединить. В данном случае, это [df1, df2, df3]. Метод concat объединяет эти объекты по оси столбцов (по умолчанию), что означает, что каждый столбец из каждого объекта DataFrame будет добавлен в результирующий объект DataFrame. В результате выполнения этого кода, df будет новым объектом DataFrame, который будет содержать все столбцы из df1, df2 и df3. Если у этих объектов DataFrame есть дублирующиеся столбцы, они будут объединены в результирующем объекте DataFrame.
Если изменим на df = pd.concat([df1, df2, df3], ignore_index=True), добавив ignore_index=True, то индекс объединенных объектов будет проигнорирован, и новый объект DataFrame df будет иметь порядковый индекс, начиная с 0. То есть, новый объект DataFrame не будет иметь никаких уникальных значений индекса, а будут использоваться просто числовые индексы.
concat для объединения объектов DataFrame по оси столбцов (axis=1), и если объекты DataFrame имеют разные количества строк или имена столбцов, то результат объединения может содержать значения NaN в местах, где значения отсутствуют.
Метод merge()
merge в pandas используется для объединения двух или более объектов DataFrame на основе совпадений значений в определенных столбцах.pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None), где:left и right — объекты DataFrame, которые нужно объединить.
how — определяет, как будут объединены объекты. Возможные значения: ‘inner’ (внутнее объединение), ‘outer’ (внешнее объединение), ‘left’ (левое внешнее объединение) и ‘right’ (правое внешнее объединение).
on — столбец или список столбцов, по которым будут выполняться объединения.
left_on и right_on — столбцы left и right, по которым будут выполняться объединения.
left_index и right_index — если True, то будут использоваться индексы объектов left и right для объединения.
sort — если True, то результат объединения будет отсортирован по указанным столбцам.
suffixes — пара значений, определяющих суффиксы, которые будут добавлены к именам столбцов в результате объединения.
copy — если True, то будет создана копия объектов left и right перед объединением.
indicator — если True, то в результирующий объект DataFrame будет добавлен столбец с указанием типа объединения.
validate — если True, то будет выполнена проверка наличия уникальных значений в столбцах, которые будут использоваться для объединения.
для примера создадим датафреймы
df1 = pd.DataFrame({'город': ['Нью-Йорк', 'Лос-Анджелес', 'Москва', 'Петербург', 'Пекин', 'Шанхай'],
'страна': ['США', 'США', 'Россия', 'Россия', 'Китай', 'Китай']})
df2 = pd.DataFrame({'город': ['Нью-Йорк', 'Лос-Анджелес', 'Москва', 'Петербург', 'Пекин', 'Шанхай'],
'численность населения': [17843000, 3971000, 12192000, 6175000, 21549000, 24150000]})
merge() на DataFrame df1. Метод merge() используется для объединения двух DataFrame на основе общего столбца или столбцов. В данном случае, df1 и df2 — это два DataFrame, и мы хотим объединить их на основе столбца город. Пандас сам будет объединять по столбцам с одинаковыми названиями, т.к. мы не указали это явно. Параметр how='left' указывает, что мы хотим выполнить левое внешнее объединение, то есть включить все строки из df1, даже если в df2 нет соответствующих значений для некоторых городов. В результате выполнения df1.merge(df2, how='left') мы получим новый DataFrame, который будет содержать все столбцы из df1, а также столбец численность населения из df2. Если в df2 нет значения для определенного города в df1, то для этого города будет установлено значение NaN в столбце численность населения.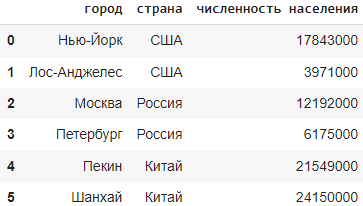
Скользящие окна. Метод rolling()
Скользящие окна в pandas — это особый тип окон, которые создаются при использовании метода rolling() для создания скользящих окон. Скользящие окна представляют собой последовательность значений, которые двигаются по окну, и позволяют выполнять операции над этими значениями.
rolling() — это метод в библиотеке pandas, который используется для создания скользящих окон. Скользящие окна позволяют выполнять операции над последовательностью значений, которые двигаются по окну.
Синтаксис series.rolling(window=N, min_periods=N, center=False, win_type=None, on=None, axis=0, closed=None), где:
window — размер скользящего окна.
min_periods — минимальное количество periods (значений), необходимых для вычисления значения в скользящем окне. Если количество periods меньше min_periods, то значение будет установлено в NaN.
center — если True, то скользящее окно будет сдвигаться по центру, если False, то по левому краю.
win_type — тип скользящего окна. Доступны следующие типы:
boxcar, triang, blackman, hamming, bartlett, parzen, bohman, blackmanharris, nuttall, barthann, kaiser, gaussian, general_gaussian, slepian, exponential, linear_weights, quadratic_weights, cubic_weights, cosine_weights, hamming_weights, triangle_weights.
Создадим датафрейм
df = pd.DataFrame({
'col1': [1,2,3,4,5],
'col2': [10,11,12,13,14]})df.rolling(3) — получим результат Rolling [window=3,center=False,axis=0,method=single].Здесь window=3 указывает размер скользящего окна, равный 3. Это означает, что скользящее окно будет содержать три значения.
center=False указывает, что скользящее окно будет сдвигаться по левому краю. Если бы center=True, то скользящее окно было бы сдвигаться по центру.
axis=0 указывает, что скользящее окно будет создаваться по оси 0 (по умолчанию). Если бы axis=1, то скользящее окно было бы создаваться по оси 1.
method=single указывает метод, который будет использоваться для вычисления значения в скользящем окне. Здесь используется метод single, который вычисляет значение как среднее значение в скользящем окне.
Выполним цикл, в котором будм выводить на печать скользящее окно из трех строк. В первый раз увидим 1 строку, во второй 2, в третий 3 и далее окно будет скользить вниз и содержать в себе 3 троки
for window in df.rolling(3):
print(window)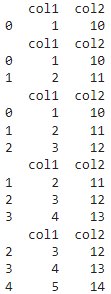
далее выполним df. rolling(3).sum(), для вычисления суммы значений в скользящем окне размера 3 по оси 0 (по умолчанию). Каждый раз при перемещении окна вперед, будет выводиться новое скользящее окно. Метод sum() вычисляет сумму значений в каждом скользящем окне и выводит сумму значений в этом окне.
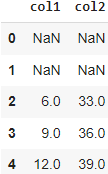
min_periods=1 указывает, что в скользящем окне должно быть как минимум 1 период (значение) для вычисления значения. 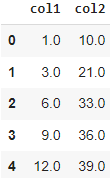
step=2 указывает, что скользящее окно будет перемещаться с шагом 2 значения вперед при каждом перемещении. 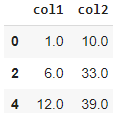
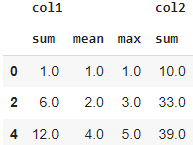
Тип данных Datetime, Timestamp. Их свойства и методы. Функция pd.to_datetime( )
В библиотеке pandas тип данных datetime используется для работы с датами и временем. Объекты этого типа хранят информацию о дате и времени в формате, который позволяет выполнять различные операции и вычисления.
В объектах типа datetime можно получить доступ к различным свойствам и методам, например таким как:
year— год даты.month— месяц даты.day— день даты.hour— час времени.minute— минута времени.second— секунда времени.microsecond— микросекунда времени.
Создадим датафрейм
df = pd.DataFrame({
'col1': ['20-05-2025','21-05-2025','22-05-2025','23-05-2025','24-05-2025','25-05-2025','26-05-2025','26-05-2025','26-05-2025', '27-05-2025', '28-05-2025', '29-05-2025', '30-05-2025','31-05-2025','01-06-2025','02-06-2025'],
'col2': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16]})
df.info()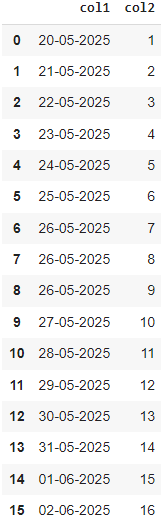
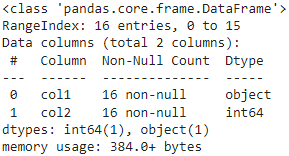
'col1' преобразуется в тип данных datetime64[ns],а .info() — это метод, который выводит информацию о типе данных и других характеристиках DataFrame. В данном случае, он выводит информацию о типе данных и других характеристиках DataFrame после преобразования столбца 'col1' в тип данных datetime64[ns].
Функция pd.to_datetime()
Функция pd.to_datetime() из библиотеки pandas используется для преобразования объектов в тип данных datetime. Она позволяет преобразовывать различные форматы дат и времени в объекты типа datetime.
Синтаксис pd.to_datetime(arg, errors='raise', dayfirst=False, yearfirst=False, utc=None, format=None, exact=True, unit='ns', infer_datetime_format=False, origin='unix', cache=True), где:
arg — объект или массив объектов, которые нужно преобразовать в тип данных datetime.
errors — указывает, как обрабатывать ошибки при преобразовании. Возможные значения: 'raise' (вызывает исключение), 'ignore' (пропускает ошибки) или 'coerce' (преобразует несовместимые значения в NaT или другое значение по умолчанию).
dayfirst — если установлено в True, то при обработке дат будет предполагаться, что день и месяц поменяны местами. По умолчанию установлено в False.
yearfirst — если установлено в True, то при обработке дат будет предполагаться, что год и день поменяны местами. По умолчанию установлено в False.
utc — если установлено в True, то значения будут преобразовываться в UTC. По умолчанию установлено в None, что означает не выполнять преобразование в UTC.
format — строка или список строк, которые указывают формат даты и времени. Если не указан, функция будет пытаться автоматически определить формат.
Объект Timestamp
Timestamp в pandas — это объект, представляющий точку во времени в виде даты и времени. Он является специализированным типом данных в pandas, который используется для представления дат и временных значений в DataFrame или Series.
Pandas представляет объект Timestamp, который может служить заменой объекта datetime. Объекты Timestamp и datetime можно считать братьями; в экосистеме pandas их часто можно использовать взаимозаменяемо. Timestamp расширяет функциональные возможности объекта datetime. Конструктор Timestamp доступен на верхнем уровне pandas; он принимает те же параметры, что и конструктор datetime. Первые три параметра, задающие дату (year, month и day), являются обязательными. В pandas объект Timestamp считается равным объекту date/datetime, если они оба хранят одну и ту же информацию.
Класс Datetime представляет собой обобщенный тип данных для работы с датами и временем в pandas. Он используется для создания объектов типа Timestamp, которые представляют точку во времени в виде даты и времени. Класс Datetime предоставляет различные методы и свойства для работы с датами и временем, такие как strftime, to_period, tz_convert, floor, ceil и другие.
Класс Timestamp, с другой стороны, представляет собой конкретный тип данных в pandas, который используется для представления точки во времени в виде даты и времени. Он является подклассом класса Datetime и наследует все его свойства и методы. Класс Timestamp также имеет свои собственные методы и свойства, такие как day_name, weekday, days_in_month, to_pydatetime и другие.
Таким образом, свойства и методы классов Datetime и Timestamp не полностью одинаковы. Класс Timestamp наследует свойства и методы от класса Datetime, но также имеет свои собственные.
Timestamp имеет множество полезных методов и атрибутов, которые позволяют выполнять различные операции и извлекать информацию о дате и времени.
Свойства и методы Timestamp
.dt — это метод, который используется для доступа к различным методам и свойствам даты и времени. Этот метод применяется к объектам типа Timestamp или DatetimeIndex в DataFrame или Series.
Например, вы можете использовать .dt.year для получения года из дат, .dt.month для получения месяца из дат и т.д. Например:
df[‘col1’].dt.year # получить год из дат в столбце ‘col1’
В библиотеке pandas есть несколько свойств и методов, которые позволяют работать с датами, вот некоторые из них:
date() — возвращает часть даты из объекта datetime.
time() — возвращает часть времени из объекта datetime.
year — год из даты.
month — месяц из даты.
day — день месяца из даты.
hour — час из времени.
minute — минута из времени.
second — секунда из времени.
microsecond — микросекунда из времени.
weekday() — день недели (0 — воскресенье, 6 — суббота).
dayofyear — номер дня в году.
day_of_week: Возвращает день недели.
day_of_year: Возвращает день в году.
dayofyear: Возвращает день в году.
Подробно ознакомиться со всеми свойствами и методами Timestamp можно в официальной документации.
Пример:
import pandas as pd
# Создание DataFrame
df = pd.DataFrame({
'col1': ['20-05-2025','21-05-2025','22-05-2025','23-05-2025','24-05-2025','25-05-2025','26-05-2025','26-05-2025','26-05-2025', '27-05-2025', '28-05-2025', '29-05-2025', '30-05-2025','31-05-2025','01-06-2025','02-06-2025'],
'col2': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16]
})
# Преобразование значений в столбце 'col1' в формат даты и времени
df['col1'] = pd.to_datetime(df['col1'], format='%d-%m-%Y')
# Добавление новых столбцов с различными атрибутами даты и времени
df['day_name'] = df['col1'].dt.day_name() # Название дня недели
df['weekday'] = df['col1'].dt.weekday # День недели (числовой индекс)
df['dayofyear'] = df['col1'].dt.dayofyear # День года
df['days_in_month'] = df['col1'].dt.days_in_month # Количество дней в месяце
df['day'] = df['col1'].dt.day # День месяца
df['day_of_year'] = df['col1'].dt.day_of_year # День года
df['month'] = df['col1'].dt.month # Месяц
df['year'] = df['col1'].dt.year # Год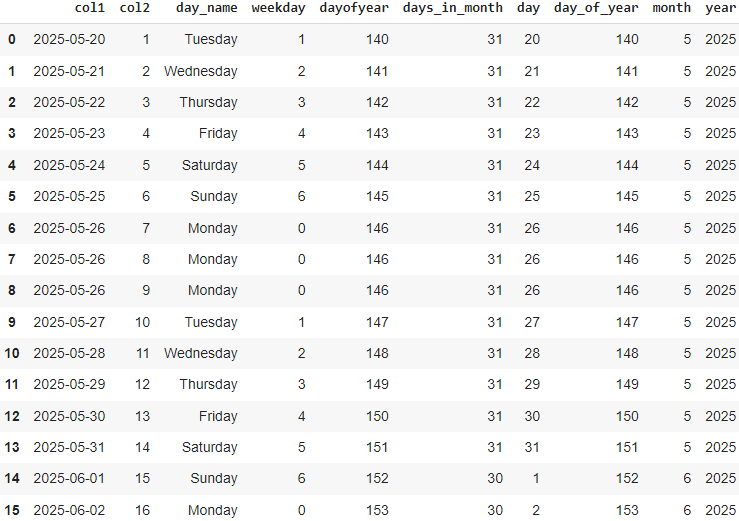
Чтобы эти свойства и методы применить к конкретной дате использовать .dt уже не нужно. Например:
print(df.loc[0,'col1'])
print(df.loc[0,'col1'].day)
print(df.loc[0,'col1'].day_name())
print(df.loc[0,'col1'].weekday())
print(df.loc[0,'col1'].day_of_year)
print(df.loc[0,'col1'].month)
print(df.loc[0,'col1'].year)
Диапазон дат
date_range — это функция в pandas, которая используется для создания последовательности дат с указанной частотой. Она генерирует объект DatetimeIndex, который содержит регулярную последовательность дат.
Синтаксис pd.date_range(start=None, end=None, periods=None, freq=None, tz=None, normalize=False), где:
start — дата начала последовательности дат.
end — дата конца последовательности дат.
periods — количество дат в последовательности.
freq — частота (интервал) между датами. Например, ‘D’ для дневной частоты, ‘W’ для недельной и т.д.
tz — временная зона.
normalize — если True, даты будут выровнены по дню месяца.
Например:
import pandas as pd
date_range = pd.date_range(start='2024-01-01', end='2024-05-31', freq='D')
print(date_range)
print(type(date_range))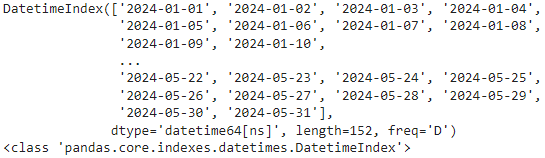
Здесь создается последовательность дат с помощью функции date_range. Параметры start и end указывают начальную и конечную даты последовательности. Параметр freq указывает частоту (интервал) между датами, в данном случае ‘D’ означает ежедневную частоту. date_range возвращает объект DatetimeIndex, который содержит последовательность дат от 1 января 2024 года до 31 мая 2024 года с интервалом в один день.
<class 'pandas.core.indexes.datetimes.DatetimeIndex'> — это класс объекта DatetimeIndex в библиотеке pandas. DatetimeIndex — это специальный индекс в pandas, который представляет собой последовательность дат и времени. Он используется для индексации данных в pandas DataFrame. DatetimeIndex предоставляет множество полезных методов и свойств для работы с датами и временем. Например, вы можете использовать методы для получения информации о датах, такие как день недели, месяц и год, или для выполнения операций над датами, таких как сортировка, фильтрация и группировка.







